
The End of Software, Long Live Software
The Rise of the Agent

Since the outbreak of the industrial revolution, human society has undergone four rounds of technological revolution, and each technological change can be regarded as the deepening of automation technology. The conflict and subsequent rebalancing of efficiency and employment are constantly being repeated in the process of replacing people with machines. When people realize the new wave of human economic and social development that is created by advanced technological innovation, they must also accept the “creative destruction” brought by the iterative renewal of new technologies.
-Shen and Zhang, The Impact of Artificial Intelligence on Employment: the Role of Virtual Agglomeration.

The Emergence
The end of software is upon us.
The rise of the AI Agent—artificially intelligent autonomous software that acts on your behalf with limited intervention—has dawned a new era of “Software 2.0” (coined by the legendary Andrey Karpathy).
Some believe that this is the end of software. That belief is foolish.
Software 1.0—code forged from the tedious review of endless documentation—is dead, indeed.
But we are not at Software 2.0 according to Karpathy’s definition. Instead, we’re at something like Software 1.9—AI boosted software with humans in the loop1.
And my view is that Software 2.0 may not come for a long time.
Not because we won’t be able to do it, we are closer everyday but because how people think about software agents today is wrong.
AI Agents
AI Agents emerged from people tinkering with LLMs to automate tasks. Simon Wilson was one of the more notable software engineers publicly building in this space. Eventually startups like Devin from Cognition came into the picture. AI Agents became appealing to investors and it has become one of the most exciting investment areas.
A major appeal of AI Agents is the expectation that it will significantly reduce the cost of building software. I think they will reduce the cost of software but, counterintuitively, I believe they will also make software much more complex.
That’s a good thing because we need more software in the world and we also need to migrate a lot of old software (e.g., payments). As it turns out, much of what we take for granted and assume is simple is actually quite complex (again, payments).
Even if AI Agents get better there’s still an accountability problem. It turns out humans like having a person or legal entity they can hold accountable when things don’t work. More practically, using generative models to write all of your code without any supervision could result in frequent breaking changes of APIs (i.e., instability of your product).
People want reliable software.
Said another way, we want deterministic behavior in our software and generative models are inherently probabilistic.
I’m sure there are ways we can modify the context or prompt to say “don’t refactor the code like crazy all of the time and introduce breaking changes”, but that won’t address the accountability problem and I’m skeptical that the reliability piece can be completely solved without a human in the loop.
Software engineers will become more impactful but they will have to expand their knowledge and skillset quite a bit more…the good news is that LLMs are great tools for this. So Software 1.9 has already supercharged engineers that use AI.
“LLMs as a Copilot” seems to be the consensus opinion among most LLM users anyway, so I’m not saying anything terribly controversial or novel here.
The end state is that software engineers will become gatekeepers of the code while agents will become the actors.
How?
The Agent of Orchestration
People love chat bots.
Maybe it’s the lazy nature of “Tell me about X” and suddenly you’re given a nicely summarized piece of content about some arbitrary topic, maybe it’s something else—probably it’s the preference for laziness.
The laziness implies that humans really like flexibility in the input—i.e., I give the computer a command (a prompt or request) and the computer does the thing.
So the thing is really important. And what we actually want is software that dynamically orchestrates operations probabilistically and executes operations deterministically. Simply, if a customer changes what they want, the computer should do something different but always do the same thing for the same input so long as you believe the customer wants that thing.
This means agents should be using existing software and that humans should be spending time making resilient and high-performing software. Probably humans shouldn’t use agents to write entire enterprise-grade applications (i.e., high stakes production software where money is on the line—hello Fintech!) without humans in the loop.
I should note that “high stakes production software” is a really important phrase. AI Agents can be autonomous proportional to the tolerance for errors. In less regulated or lower-stakes areas (i.e., not Fintech, Healthcare, Education, etc.), AI Agents will likely do a lot more.
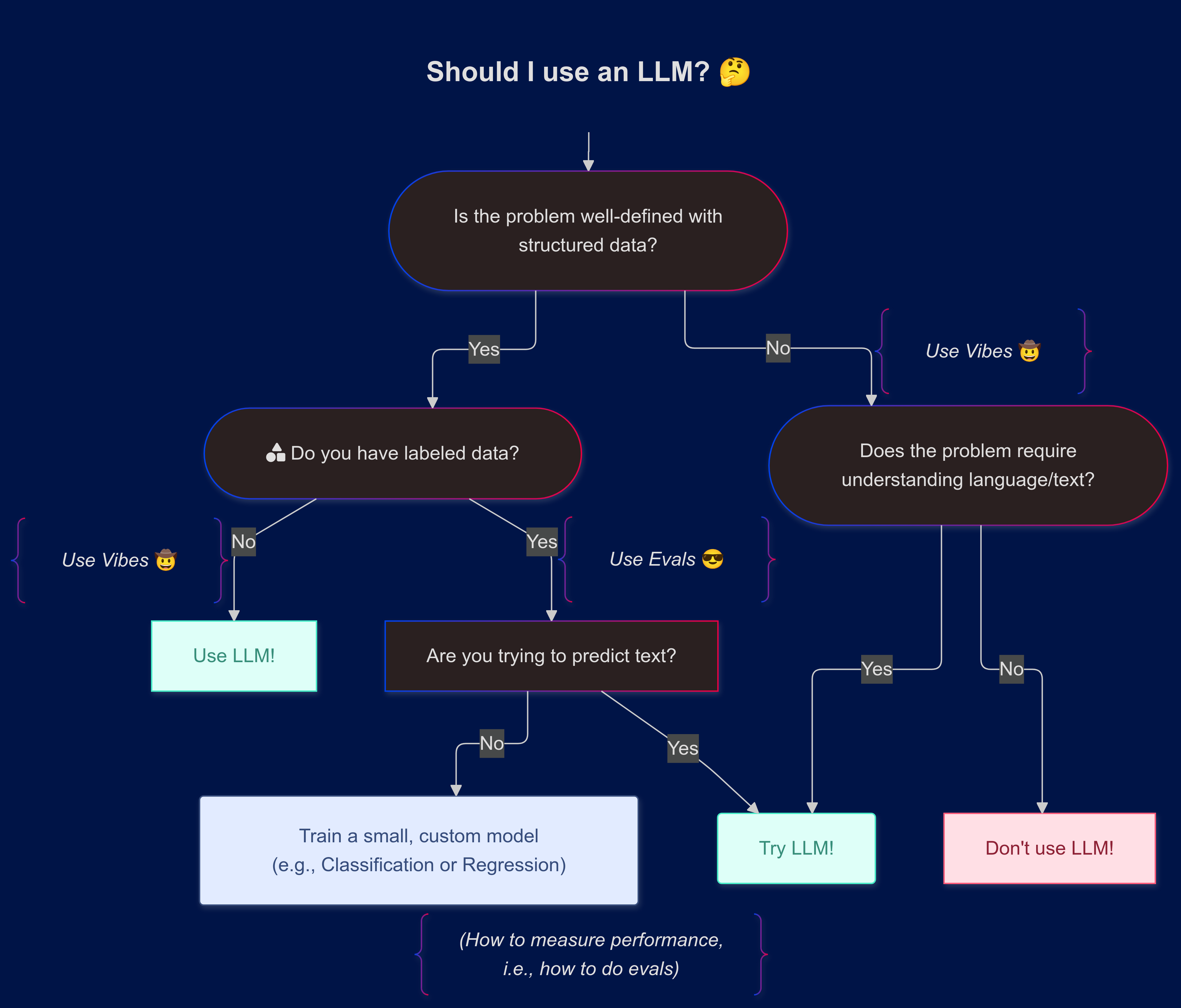
Evals Are All you Need

AI is powered by data. To build powerful AI you need the ability to measure the performance of your model and actions on some set of data. This is called model evaluation, or “evals”.
Evals require data, obviously. Data is generated by a process that you are quantifying.
To quantify something correctly, you have to measure it in code and this is the most underappreciated thing in AI/ML—probably because it’s boring.
For Agents and AI to work more broadly, you need high quality data and that means you need high quality tracking systems2.
So, tracking systems and the data they produce are the foundational components of AI, without them no amount of math, LLMs, or other AI will make you successful.

To make this more concrete, let’s consider a chatbot (or code generator): the data is the actual words/tokens authored. For an AI Agent that orchestrates operations, this would be the sequence of events and the actions it took encoded systematically.
Let’s say you have a bunch of financial documents and you want to summarize them for a customer and let the customer ask questions about the documents.
There are approximately3 four things that you need to do:
Parse a bunch of data.
Extract the most relevant sections of the documents to use in Retrieval Augmented Generation (RAG).
Note, it is terribly underappreciated that retrieving a set of documents for RAG reduces to a classification problem at the sentence/chunk and document level, but the community settled on cheap heuristics because it’s easy to compute cosine similarity and it works surprisingly well in practice. Still surprises me. 🤷♂️
Generate an initial summary of the documents.
Answer the questions with the best context (using the extracted documents).
We want (1) and (2) to be deterministic and (3) and (4) to be probabilistic. Since (3) and (4) are generative, again, they are probabilistic by definition.

An agent executing these four steps while interfacing with a human in a production application means that the process won’t actually occur sequentially. You probably will have to parse new documents, answer other questions, or have a human intervene (i.e., in the loop).
The key detail is that agents need to be able to deterministically parse old documents the same way while also handling new/unseen formats.
The best way to handle deterministic parsing is not to just throw the document at ChatGPT (that’s a good idea when you’re dealing with a cold start4 in general).
The actual solution is two-fold: (1) throw it into ChatGPT and cross your fingers and (2) use a pseudo-deterministic approach.
A pseudo-deterministic involves the agent first attempting to execute existing code. If the code fails, the agent then parses the data and generates new code to handle the new format. Next the agent would submit this updated code as a Pull Request to be reviewed or modified by a human—i.e., you need a human-in-the-loop. Once approved, the new code would be incorporated into the application.
You can think of this approach as self-evolving software with a human-in-the-loop and I believe this is the way that Agents will prove to be the most impactful and build resilient software.
Data is the Foundation
Outside of infrastructure and compute, data is the competitive advantage for every major company in the AI race and that’s because ultimately those companies hold the proprietary information of an explicit goal and the operations needed to accomplish it—i.e., training data.
So, the biggest obstacle in everyone’s way of successfully launching production grade AI Agents is the ability to correctly measure the thing they’re trying to automate.
The Future of Agents

The benefit of starting narrow is that you’ll be able to build a training data moat that will create an actual competitive advantage.
So, builders should start small, invest in measuring every single step of the process that you’re automating, ensure you’re emitting high quality data, measure the accuracy of your agent, and then fine tune your model based on your proprietary data (if necessary).
Friday Harbor, Benchmark, and Cleric are great companies that are already building products this way.

Closing Thoughts
I’ve said before, the future will use more AI and software, not less. I am excited about a future that runs efficiently, solves novel problems, and that forges a brighter world for humanity.
Technology, with its many flaws, has helped reduce the suffering for billions of people and AI Agents will accelerate this by orders of magnitude.
The most exciting thing is that we are still so early and there’s a whole world to build.
Happy building!
-Francisco 🤠
Some Content Recommendations
Jason Mikula interviewed the one and only Max Levchin, CEO of Affirm.
Alex Johnson wrote about the Future of the Financial Data Economy.
Simon Taylor shared the Top 10 Fintech Brainfood Rants of 2024.
Nik Milanović asked an important question: “Would you let an AI agent make payments for you?” The answer will be yes, with a human (yourself) in the loop.
Postscript
Did you like this post? Do you have any feedback? Do you have some topics you’d like me to write about? Do you have any ideas how I could make this better? I’d love your feedback!
Feel free to respond to this email or reach out to me on Twitter! 🤠
Though, increasingly less.
I would like to scream this in people’s faces.
In a real production application, there actually more.
A slight abuse of language from Recommender Systems but a cold start is simply not having prior knowledge about a process you are trying to predict so you start out with an often bad or random prediction.
Enjoying this conversation on the evolution of software. One thought on: "People want reliable software" and "we want deterministic behavior in our software." IMO they are different things, but depends on your definition of "reliable." I'd say people want "software that does what they want it to do," which is going to become a looser and looser concept over time. In some cases (fintech), the rules are stricter, and LLMs are not only probabilistic but objectively fail at following strict rules. Humans have lived without determinism in practice for a long time, so I think we're okay with handling that :)