
Production Artificial Intelligence
On the future of Software and AI


Auto-Regressive LLMs are not controllable and are not sufficient to reach human-style intelligence. They will disappear in a few years. Future AI systems will use a different blueprint.
Large Language Models
LLMs are incredible and they have already changed the future of humanity.
They are an important step along the path to Artificial General Intelligence…but they are not the end game.
As Yann LeCun stated, this is largely because of their auto-regressive nature; i.e., they are built to maximize the probability of the next token. This works surprisingly well in practice…but it has its limitations.
Agents
Some have suggested that LLMs could be a new Operating System. I think it’s a reasonable conclusion to see something as amazing as GPT Agents and conclude it’s going to be the next wave of an OS but I disagree.
LLMs are inherently probabilistic.
That’s bad for programming. In software, we want pure determinism (maybe stable APIs) and for some reason people seem to ignore this.
Regardless, using LLMs for product experiences (e.g., ChatBots or a narrow task like writing specific types of writing) seems to be an increasingly common use case.
When the cost of being wrong is low, it works great but when the cost of being wrong is high, that can be massively consequential.
Hallucinations
When the probabilistically generated sequence of tokens goes in a direction users don’t like, we call this hallucination. Hallucinations are reasonably well understood but current approaches to prevent them are still not effective for the the long tail of problems…which is because the long tail is something much more challenging—general understanding, planning, and decision making in a world with a lot of uncertainty.
Beyond auto-regressive methods being insufficient to model the world, I would add that latent embedding representations are also insufficient.
Let me elaborate on what that means.
Representations, Vector Embeddings, and Feature Engineering
In the world of LLMs you hear a lot about tokens. In short, tokens are numeric representations of words or special characters. Machine learning algorithms do their mathematics using numbers and these tokens are pointers to a location in a matrix. When the token is fed through a neural network it is usually represented through a simple binary-encoding in a matrix—i.e., 0 or 1 indicating whether or not the token was present.
Vector Embeddings
Here’s a simple example of three documents with five unique words (tokens).
Binary encoding, while simple, turns out to be surprisingly effective and it is a basic example of featurization.
Featurization is the process by which some phenomenon is quantified or represented to enable a computer to do mathematics. In the simple regression setting you can think of age, education, or employment status as examples of other features. More fundamentally, these features exploit the structured nature of data and represents it explicitly.
For LLMs, we extend this encoding from a single binary representation to a vector embedding (a list of numbers).
We learn the vector embedding representations by initializing them to some random numbers and running gradient descent during unsupervised pretraining and, through what can be only described as mathematical alchemy1, those random numbers begin to mean something.
This representation approach was made famous back in 2013 by folks at Google and the diagram below provides some simple intuition. You can take these representations and can apply things like King - Queen ≈ Woman2.
It turns out these representations, along with new auto-regressive architectures, started achieving the state of the art performance for various NLP benchmarks.

The Old Ways
In the old days, before the dominance of Deep Learning, researchers used to do explicit feature engineering as a part of their modeling pipeline.

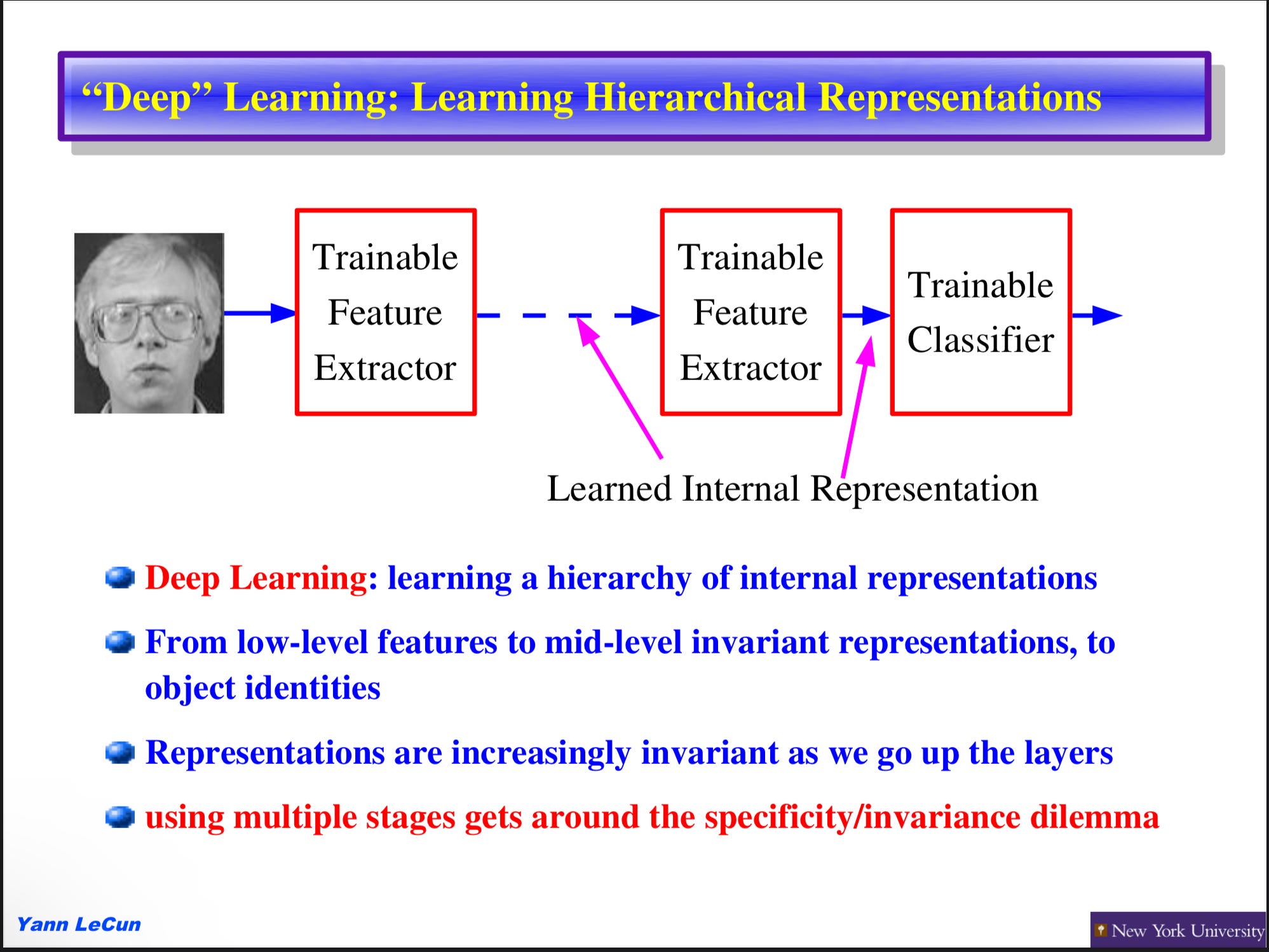
Explicit feature engineering is a generalization of the binary encoding example and it has a rich history in natural language processing, computer vision, and tabular data mining. In fact, explicit feature engineering and XGBoost still represent a meaningful share of tabular machine learning in production today.
Feature Engineering
Explicit feature engineering is really just writing code to make quantitative representations of things, often with the goal of predicting something (supervised learning). For example, if you want to build a machine learning model to generate product recommendations, you would engineer features that quantified what a user likes, what they interact with, what they are interested in, what’s novel to them, and really whatever else you can think of and measure (even crudely).
As it turns out, feature engineering can get quite involved and you can end up writing very complex feature transformations, which means you end up with very complex code, which means the engineering systems to deploy them can be quite complex, too. This is because all of those complex transformations depend on different data sources with different shapes, integration patterns, and tradeoffs that really make the engineering challenging at scale.
Human Constructs
I want to pause for a moment here.
These features are usually representations of human constructs or crude approximations for structural constructs. Human constructs are exactly what they sounds like, things in the world that we humans define, categorize, and name.
They are very different than the laws of physics or mathematics that can be rigorously derived and proved—somehow we encoded the language of the gods and in doing so we discovered that some representations are explicit; indeed, one plus one provably equals two. Human constructs are also very different than representing a raw image in machine learning where models learn the latent representation of objects we classify with our set of arbitrary categories.
In this case, “latent representation” is what I would call structural (i.e., a representation of true nature) compared to the category, which is a human construct (i.e., today we call this thing a Zebra but tomorrow we could call it something else just because our view of the world changed).
To summarize, when we define, categorize, or name something usually there is additional meaning behind it and it turns out embeddings approximate that meaning very well using a latent high dimensional representation.
Unfortunately, that representation is hard to make precise statements about…and it also turns out there are other explicit things we are representing and machines should use that information because we humans do.
An Example
Suppose you wanted a multi-modal generative language model to take an image as input and tell you what’s in it. Let’s say you want the LLM to do this. To make it concrete, let’s suppose you uploaded the Zebra below.

The inputs would probably be (1) a query such as “what is this thing?” and (2) the image of the Zebra. The ideal output would be “This is a Zebra” or simply “Zebra”.
In the silly diagram above I’ve outlined how the word token can relate to a latent embedding vector versus explicit feature engineering. For convenience I made the embedding vector the same length as the number of features but they’re entirely unrelated3. I also gave examples of features you might see in practice but they all would rely on another vision model to construct them. Ignoring that massive detail, you can see the obvious difference being that features represent specific constructs we define and embeddings learn a construct that is difficult for us to derive clarity from—what does the “0.2” in the second element of the word embedding precisely mean? We don’t really know, that’s why it’s latent! For explicitly labeled features, we do! But the cost of creating these features is high because it is entirely manual and often requires domain expertise. That doesn’t scale very well at all but it is terribly effective.
We shouldn’t have to choose one or the other, we can and should use both.
Prompts, RAG, and Zero-shot Learning
Prompting is the starting point for people using LLMs in their products and this usually works quite well. The next step is to add Retrieval Augmented Generation (RAG) and then the next step after that is to use Fine Tuning. It’s worth mentioning that some people have moved to RAFTA (Retrieval Augmented Fine Tuning) which I would include in Fine Tuning.
These tools are all mechanisms aimed at reducing hallucinations and they work well in some cases…but (1) any autoregressive generative model will expose some non-zero risk of hallucination and (2) the RAG approach heavily relies on these embeddings and a single convenient distance metric.
The only way to reduce hallucinations to something more palatable (maybe for higher stakes use cases) is to confine the output space and I don’t know if current approaches will ever be able to do that without more fundamental changes.
Facts, Knowledge Graphs, Search, and Retrieval
Along with what Yann called out, I believe five additional things will happen as researchers and practitioners continue to make progress on more general understanding.
We will need a mechanism to explicitly encode facts4 and relationships. I believe Knowledge Graphs will be a useful tool to enhance RAG.
Search and Retrieval approaches will need to explicitly incorporate these facts into the documents used for generation.
We will have to develop new model architectures to exploit these facts and structure of the data.
We will need some generic framework to learn or generate explicit feature representations that are interpretable to humans.
We will use more fine tuning on smaller, specialized models.
At the core of (1)-(3) and maybe even (4) is feature engineering.
Fine Tuning is The Way
Fine tuning is how all of the successful machine learning applications have quietly improved the world around us for decades, so it is obvious that this is the way. Of course, RAG, prompting, feature engineering, and other levers are useful to improve model behavior but fine tuning lets you explicitly optimize an objective and that’s usually the goal of some software system, so it feels very natural to me…but most users of models are preferring to use one giant model and wait for it to continue to get better. That approach certainly isn’t wrong but I do think there is a lot of utility in narrower models…and the open source community seems to be trending that way.
So, what does all of this mean for Production Artificial Intelligence?
Production Artificial Intelligence
As Knowledge Graphs, features, and specialized models become popular, the uninitiated will learn that running production applications using artificial intelligence requires highly optimized data systems.
From an engineering perspective, LLMs and diffusion models are convenient5 as they pose minimal data constraints6 for online inference—it is sufficient to input text to get relatively high quality output.
This convenience exploded the scale of possibilities. Historically, deploying machine learning models to production has been challenging for many companies, leading to a high failure rate of machine learning projects.
In my experience, these failures are rooted in data challenges. As it turns out, for many business applications some of the biggest obstacles are not building machine learning models but building pipelines to send data from one place to another and exposing that data to customer facing product experiences.
Feature Stores
Feature Stores emerged in 2017 as the potential solution to help solve this plumbing problem and they have been very successful for many companies7. In short, these systems focus entirely on enabling machine learning engineers to get features in online production environments by plumbing the data into a centralized database that can be optimized for online, real-time retrieval.

Vector Databases
Vector databases recently became the preferred tool for Retrieval Augmented Generation (RAG) applications. A vector database is merely a narrow application of a feature store and leveraging a feature store can allow for richer context injection (e.g., relevant user data) along with the retrieved documents.
This is important to state because the current popularity of vector databases omits how LLMs can benefit from rich, structured data both in model training and at inference time.
The Future
The future of production artificial intelligence will rely more explicitly on unstructured tokens and structured data for model inference, so I believe feature stores will become the foundation of the artificial intelligence stack.
I briefly hinted at this point in my last post and I wanted to finally expand on what I meant.
I believe Feast is a solution that enables companies to deliver more products powered by machine learning to their customers easier and faster.

The Plan
My plan now is to pontificate less and code more.
I have two goals: (1) improve the Feast infrastructure and (2) build an open source consumer Fintech chatbot (reach out if you’re interested in collaborating on this).
For this newsletter, I plan to write shorter articles more frequently and focus on technical content to give updates on my progress on my two goals. If you’re interested in Feast specifics, feel free to follow Feast on LinkedIn or Twitter/X.
Closing Thoughts
I am excited by this moment in time where brilliance across the planet is united in driving AI progress forward. It is awe inspiring and I feel privileged to be along for the ride.
The path to artificial general intelligence will be paved in sophisticated software, novel learning paradigms, community collaboration, and hard work.
Happy building.
-Francisco 🤠
Some Content Recommendations
Lex Friedman interviewed the extraordinary Yann LeCun on the limits of LLMs.
Jason Mikula covered Synapse’s Bankruptcy filings in elaborate detail.
Simon Taylor wrote about Fintech’s comeback.
Alex Johnson wrote about The Servicing Imperative.
Post Script
The views expressed here are those of the author and the author alone, they do not reflect the views of his employer or previous employers.
Did you like this post? Do you have any feedback? Do you have some topics you’d like me to write about? Do you have any ideas how I could make this better? I’d love your feedback!
Feel free to respond to this email or reach out to me on Twitter! 🤠
We turn rocks into chips and from these stones and mathematics we forge glimpses of intelligence. Doesn’t that just blow your mind?
Technically the way to find this is to find the most similar word vector. For the King - Queen = Woman example you would find the word vector most similar to (e.g., using the cosine similarity) King - Queen and that would probably be Woman.
But it did make the diagram cleaner.
Outside of a subset of natural sciences, facts are a weird construct. One could argue that a “fact” is nothing more than a strong probabilistic statement and one wouldn’t be wrong. But, still, humans treat knowledge that we believe to be true with high probability differently than knowledge we treat as fact and that is something that intelligent machines should reflect, too.
Serving LLMS at scale poses significant challenges but none that limit a company’s ability to actually run the model.
This is also true for many Computer Vision applications.