
Customer Segmentation
An Algorithmic Approach


What is Customer Segmentation?
Customer segmentation (sometimes called Market Segmentation) is ubiqutous in the private sector. We think about bucketing people into k mutually exclusive and collectively exhausting (MECE) groups. The premise being that instead of having 1 strategy for delivering a product or experience, providing k experiences or strategies will yield much better engagement or acquisition from our customers.
Generally speaking, this makes sense; it's intuitive. Provide people a more curated experience and they will enjoy it more...and the more personalized the better.
Netflix, Spotify, YouTube, Twiter, Instagram, and all of the big tech companies have mastered personalization by using robust, computationally intensive, and sophisticated machine learning pipelines. But the world has been doing this for a long time—albeit much less sophisticated.
So I thought I'd give a technical demo of what customer segmentation looks like in a basic way using a fun trick I learned a long time ago.
Approaches to Customer Segmentation
The phrase "Customer Segments" tends to mean different things across different industries, organizations, and even across business functions (e.g., marketing, risk, product, etc.).
As an example, for a consumer products retailer, they may refer to customer segments using both demographic information or their purchase behavior, where a lender may refer to their segments based on credit score bands. While very meaningfully different from a business perspective, the same algorithms can be used for both problems.
Analytically speaking, I've seen Customer Segments defined really in two main ways: (1) Business Segments and (2) Algorithmic Segments. Usually executives refer to their segments in the first category and data scientists focus on the second. The first is really important organizationally because 99% of the people working with your customers don't care about how you bucketed them and customers are the most important thing, always.
...but how do you actually (i.e., in code and data) get to those segments?
Business Segmentation
Business segmentation tends to be defined by heuristics and things that make common sense. They are often built on things that are aligned with the goal of the business.
Here are some examples of segments defined by common sense:
The age of the customer (in years)
The income of the customer (in dollars or thousands of dollars)
The amount of money a customer spent in the last year
The likelihood a customer will spend money at a given store (propensity to buy)
The customer's geographic region (e.g., zipcode, state, region)
In data, some of that customer information would look something like this:

And so on.
We could apply some logic/rules/code to create segments like:
Age Segments
< 25
25-35
35-55
55+
Income Segments
< $25K
$25K-50K
$50K-100K
$100-150K
$150K+
Purchase Propensity Segments
Low: [0, 0.25]
Medium: [0.25, 0.75]
High: [0.75, 1.0]
And map that logic into our data, which would look something like this:

And so on.
Pretty simple, right? The code for this categorization is simple too (assuming you're using Pandas and Python; though it's also simple in SQL).
# Here's one example
import numpy as np
import pandas as pd
cdf['Income Bucket'] = pd.cut(cdf['Annual Income ($K)'],
bins=[0, 25, 35, 55, np.inf],
labels=['<25', '25-35', '35-55', '55+']
)This is a really helpful and simple way to understand our customers and it's the way that most businesses do analytics, but we can do more. 😊🤓
Algorithmic Segmentation
Segments defined using simple business logic are great because they are so easy to interpret, but that's not free. By favoring simplicity we have to limit ourselves to (potentially) suboptimal segments. This is typically on purpose but, again, we can do better.
So, how do we do better?
Cue statistics, data mining, analytics, machine learning, or whatever it's called this week. More specifically, we can use the classic K-Means Clustering algorithm to learn an optimal set of segments given some set of data.
To skip over many important details (that you can read more about here), K-Means is an algorithm that optimally buckets/splits/partitions your data into K groups (according to a specific mathematical function called the euclidean distance). It's a classic approach and tends to work quite well in practice (there are a ton of other neat clustering algorithms) but one some challenges are (1) choosing K and (2) explaining what a single cluster actually means to literally anyone else.
Solving (1) is relatively straight-forward. You can run K-means for some number of K from [1, m] (m>0) and choose what appears to be a K that sufficiently minimizes the within-cluster sum-of-squares. In the graph below, notice that the the majority of the variation of the clusters can be capture by k=6.
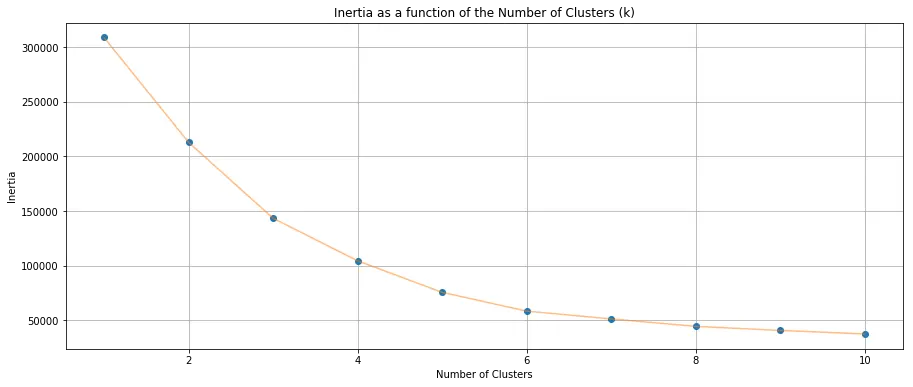
Now to (2), which is the harder challenge; i.e., telling a non-technical person what the hell your K-means cluster means other than “idk a group or something”.
Let’s start by visualizing the data to look at the clusters.
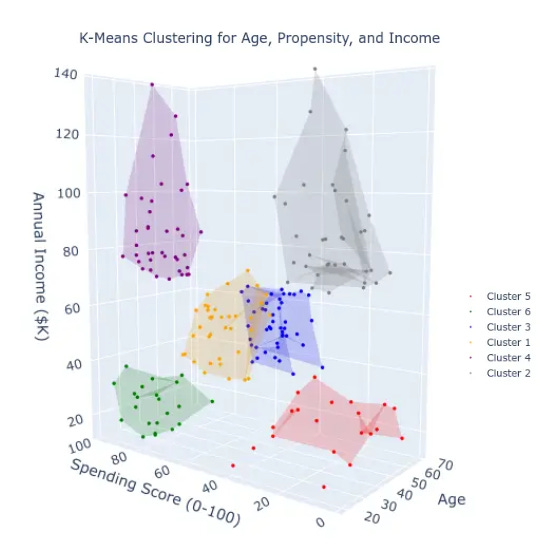
How cool, right? This little algorithm learned pretty clear groups that you can see rather obviously in the data. Impressive! And also useless to your stakeholders.
More seriously, while you can see these clusters, you can't actually extract a clear description from it, which makes interpreting it really, really hard when you go past 3 dimensions.
So what can you do to make this slightly more meaningful?
K-Means 🤝 Decision Trees
Cue decision trees. Another elegant, classic, and amazing algorithm. Decision Trees basically split up your data using simple if-else statements that are learned through sorting on steroids. So, a trick that you can use is to take the clusters from K-means and run a Multi-classification Decision Tree to predict the segment and use the learneed tree's logic as your new business logic.
I find this little trick pretty fun and effective since I can more easily describe how a machine learned a segment and I can also inspect it.
If you run the decision tree on this learned K-means, this is what the output looks like:
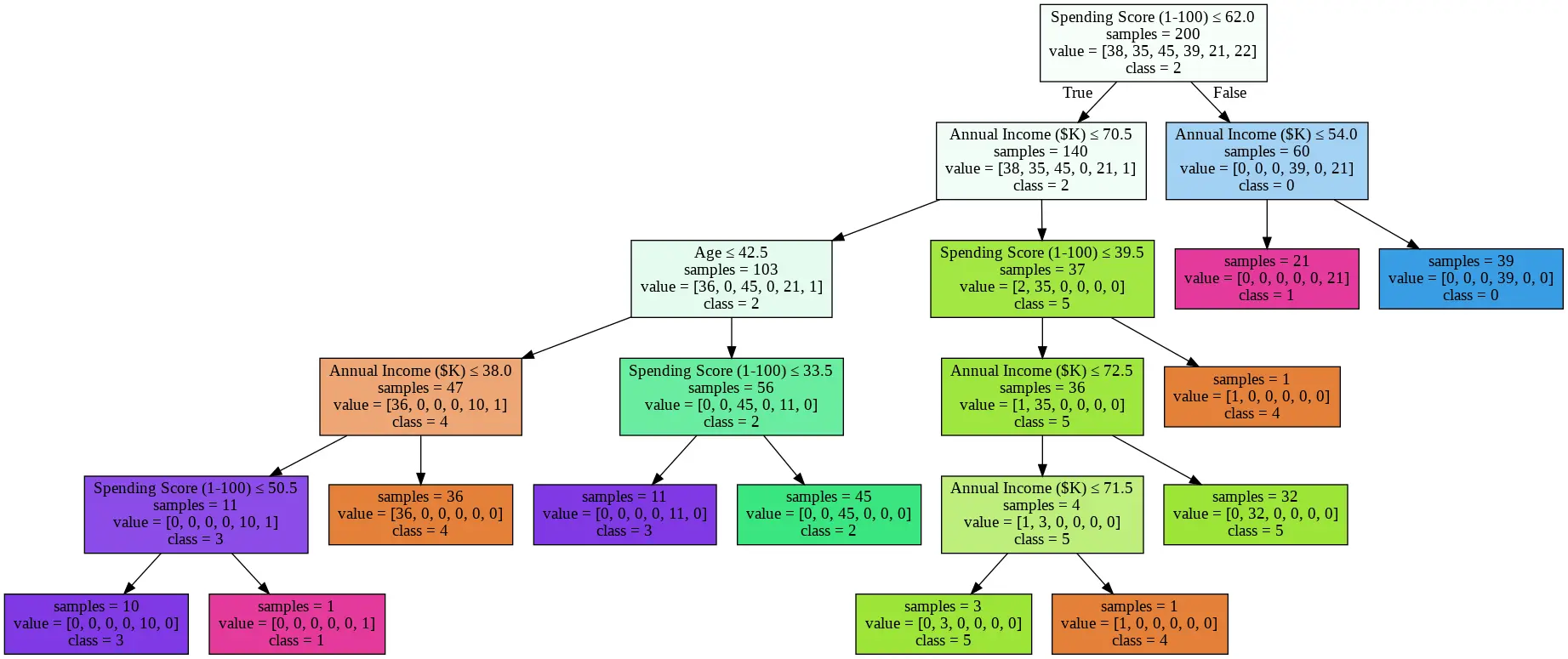
There you have it, now you have a segmentation that is closer to optimal and somewhat easier to interpret.
It's still not as readable as the heuristic approach but you could actually read through this and eventually come up with a hybrid which is why I've used it in the past. Importantly, you can dump this into some SQL logic and use it for all sorts of other impactful work (I’ve shared the code below for reference1).
import pydotplus
import pandas as pd
from sklearn.tree import DecisionTreeClassifier
from sklearn.tree import export_graphviz
from sklearn.externals.six import StringIO
optimal_clusters = 6
# 6 clusters 6 colors
xcolors = ['red', 'green', 'blue', 'orange', 'purple', 'gray']
# Chose 6 as the best number of clusters
kmeans_model = KMeans(n_clusters = optimal_clusters,init='k-means++', n_init = 10, max_iter=300, tol=0.0001, random_state= 111, algorithm='elkan')
kmeans_model.fit(X1)
cdf['pred_cluster_kmeans'] = kmeans_model.labels_
centroids = kmeans_model.cluster_centers_
display(
pd.DataFrame(
cdf['pred_cluster_kmeans'].value_counts(normalize=True)
)
)
# Train Decision Tree Classifer
clf = DecisionTreeClassifier()
clf = clf.fit(X1, cdf['pred_cluster_kmeans'])
# Predict the response for test dataset
cdf['pred_class_dtree'] = clf.predict(X1)
display(
pd.crosstab(
cdf['pred_cluster_kmeans'],
cdf['pred_class_dtree']
)
)
dot_data = StringIO()
classnames = cdf['pred_cluster_kmeans'].unique().astype(str).tolist()
export_graphviz(
decision_tree=clf,
out_file=dot_data,
filled=True,
rounded=False,
impurity=False,
special_characters=True,
feature_names=xcol_labels,
class_names=classnames,
)
graph = pydotplus.graph_from_dot_data(dot_data.getvalue())
graph.write_png("./decisiontree.png")What can you do with your new segments?
Now that you have your customer segments you can do all sorts of different things.
You can create A/B tests for site experiences, test the impact of changing prices to certain customers, or send different email campaigns to improve engagement.
In general, you can iterate differently for different groups.
How do I know if my segments are accurate?
The metric we used in the example above (i.e., the within cluster sum-of-squares / inertia) was a reasonably straightforward way to measure the accuracy of your segments from an analytical perspective, but if you wanted to take a closer look, I'd recommend reviewing individual users in each segment.
That sounds a little silly and can lead to the wrong conclusions in some cases but I firmly believe that in data science, you just have to really look at your data. You learn a lot from it, and it’s, surprisingly, often forgotten as a useful step in the work.
Unfortuantely, with clustering and segmentation there isn’t a single metric that you can use to say “these are the best”, most approaches have some caveats and work pretty well but there’s a bit of “hey, this looks good enough 🤷.”
How do I know when my segments need to change?
Segments typically change; your customers are always evolving so it's good to re-evaluate them time and again. The emergence of new segments should feel very obvious, since it may be driven by product, acquisition, or business changes.
As a concrete example, if you noticed that important businesss metrics split by your segments are starting to behave a little differently, then you can investigate whether it's driven by a change in the segments; sometimes it is, sometimes it isn’t.
Closing Thoughts
Customer segmentation is a powerful tool and can be made more efficient with some pretty standard algorithms so I hope you’ve found this overview useful. I want to restate the importance of defining your segments because they should always be specific to your business and problem.

I also want to mention that here we’ve discussed segments where you don’t have an explicit metric to optimize. If you had a specific goal in mind, e.g., understanding which segments have lower risk or higher likelihood to buy something, then you’re usually better off building a statistical/machine learning model to explicitly optimize it (assuming you have the historical data available).
Lastly, I've stored the code to reproduce this example in a Jupyter Notebook available on my GitHub (note to render the interactive 3D visualization you have to run the notebook). To get it up and running you only need to download the notebook, download the data, install Docker, and run:
docker run -it -p 8888:8888 -v ~/path/to/your/folder/:/home/jovyan/work --rm --name jupyter jupyter/scipy-notebook:17aba6048f44And you should be good to go.
Happy segmenting!
-FJA
Some Content Recommendations
What is Data Engineering? by The Pragmatic Engineer and SeattleDataGuy is an excellent piece for those wanting to learn more about one of the most important roles for technology companies.
Thanksgiving Mailbag by Jason Mikula was an excellent response to some fun questions on Twitter. Thanks for answering mine!
Payment Cards Deep Dive byFintech Explainers was awesome and I learned a lot from it, I highly recommend it!
Data Systems Tend Towards Production by Ian Macomber writes an exceptional piece on how good data work inevitably ends in a production system. It’s a great piece and an important topic I’ll write about in the future.
Postscript
Did you like this post? Do you have any feedback? Do you have some topics you’d like me to write about? Do you have any ideas how I could make this better? I’d love your feedback!
Feel free to respond to this email or reach out to me on Twitter! 🤠
As a brief aside, I love Substack but their code rendering isn’t terrible friendly, nor is their ability to render LaTeX equations. You can find a better rendered version on my blog or just look at all of the code on GitHub (though I’ll note the 3d plot doesn’t render there because it’s actually an interactive Plotly graph).
🔥🔥🔥🔥 "Segments typically change; your customers are always evolving so it's good to re-evaluate them time and again." So true, golden advice for all but especially useful for early stage startups that are targeting early adopters. Also ok for startups to change. If the segments you're helping no longer serve the business in a sustainable way, it's totally fine to change segments or go up market.