
A Decade of Risk Machine Learning
Some Lessons

The goals in statistics are to use data to predict and to get information about the underlying data mechanism. Nowhere is it written on a stone tablet what kind of model should be used to solve problems involving data.
The Two Cultures
It has been over twenty years since Professor Leo Breiman wrote the famous “Two Cultures” article. For those of us machine learning practitioners working in industry, it is Gospel.
It’s regarded so highly because, not only did he invent Classification and Regression Trees, Bootstrap Aggregating, and Random Forest, but because he changed the nature of statistics.
It was Dr. Breiman’s pragmatic perspective and thoughtful writing that shaped my approach to modeling data. I am neither Bayesian nor Frequentist, I am a Pragmatist1—choosing the tool that best works for the data.
A Decade of Chaos
I have spent one third of my life modeling data and applying machine learning to various forms of quantitative financial problems.
This past April I was invited to speak at Tecton’s apply(risk) conference and I was quite flattered by the opportunity. When I thought about what I could talk about, I settled on two things: (1) all of the mistakes I’ve made during my time doing this sort of thing and (2) demoing Feast—an open source framework maintained by Tecton and used by some of the best technology companies doing applied machine learning.
So, if you’d like to attend my talk on Tuesday May 30th at 1PM EST, use this link—it’s free. The slides are also freely available here.
Update: You can find the full recording here freely available on YouTube.

And I’ll share my notes in the rest of this post.
Introduction

I’ve written about myself before here. In this talk I aim to discuss six things.
Taking ML from 0 → 1
Building Models like building Software
Data Lineage
Common Mistakes
Risk and the Engineering of Chaos
Demoing Feast
Machine Learning: 0 → 1
If you’re just getting started with machine learning in your product, it’s worth keeping in mind a few things.
The most important of which is that you will probably spend 90% of your time at the start on the data and software work and 10% on the actual machine learning.
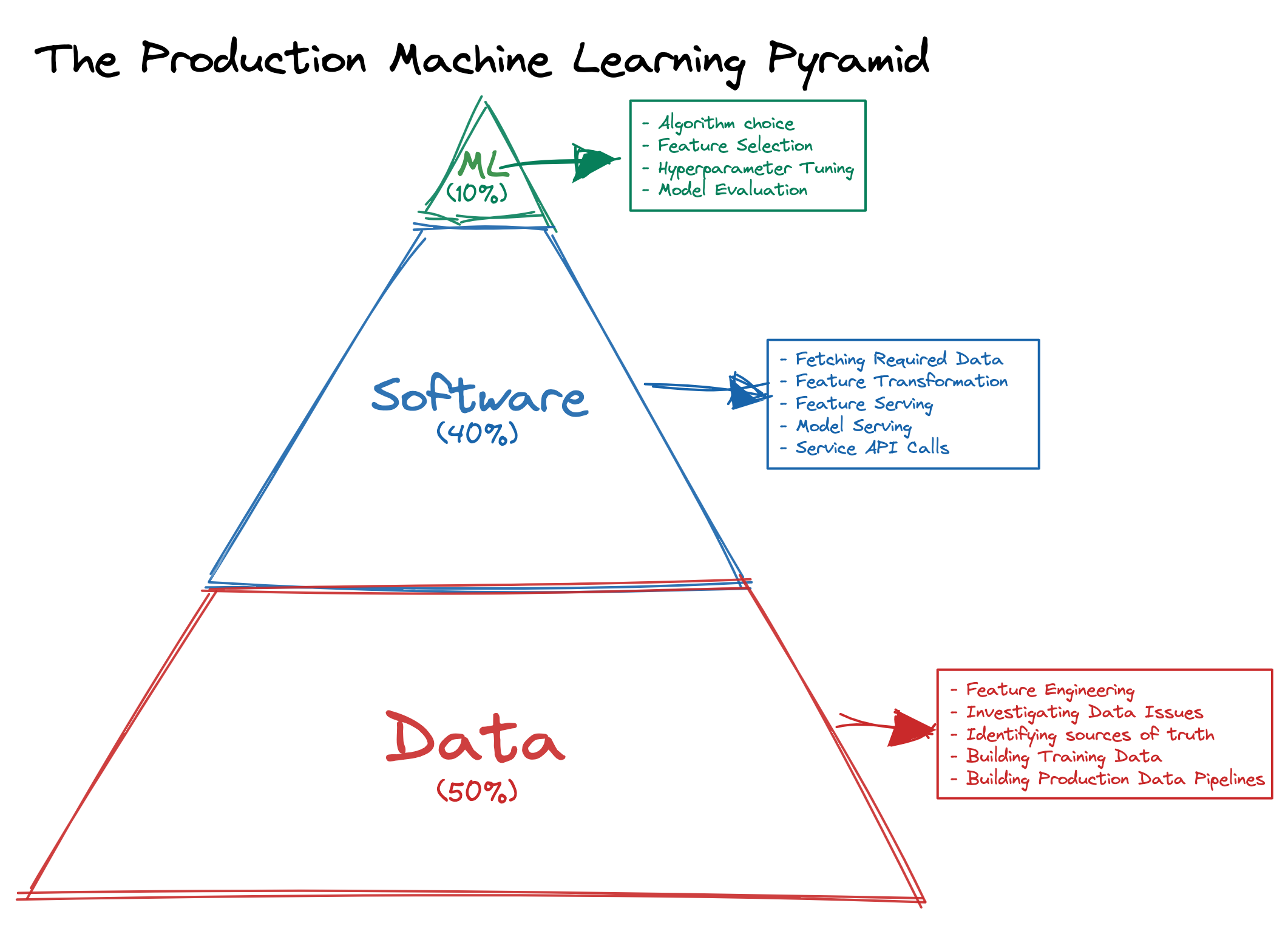
Some other useful things to keep in mind:
Data is the foundation of all machine learning models.
Great software produces good data.
Machine learning is only as good as the data it is trained on and only as useful as the software surrounding it.
Product is the foundation of customer value and machine learning will not succeed without customer value.
ML can amplify a great product experience but it won’t make a bad product experience great.
Software is the core engine and it reinforces the flywheel. ML without good software is doomed.
The Machine Learning Flywheel
Great software leads to great product experiences, which lead to lots of data, and lots of leads to great machine learning. Accomplish all four and you can unlock the Machine learning Flywheel.

Build Models like you Build Software
I’ve written before about how 87% of machine learning projects fail and that it’s mostly driven by poor engineering practices.
Data is generated through code. Models are generated through code. Not having lineage of both will result in pain. Obviously, without those things reproducibility is impossible.

More importantly, this will result in either models not getting shipped or blowing up production. So make sure you have the right engineering standards in place.
Data Producers, Data Consumers, and Data Lineage
Data Producers generally don’t know who Data Consumers are, so data transformation pipelines often break. This is an industry-wide problem, not only limited to machine learning.
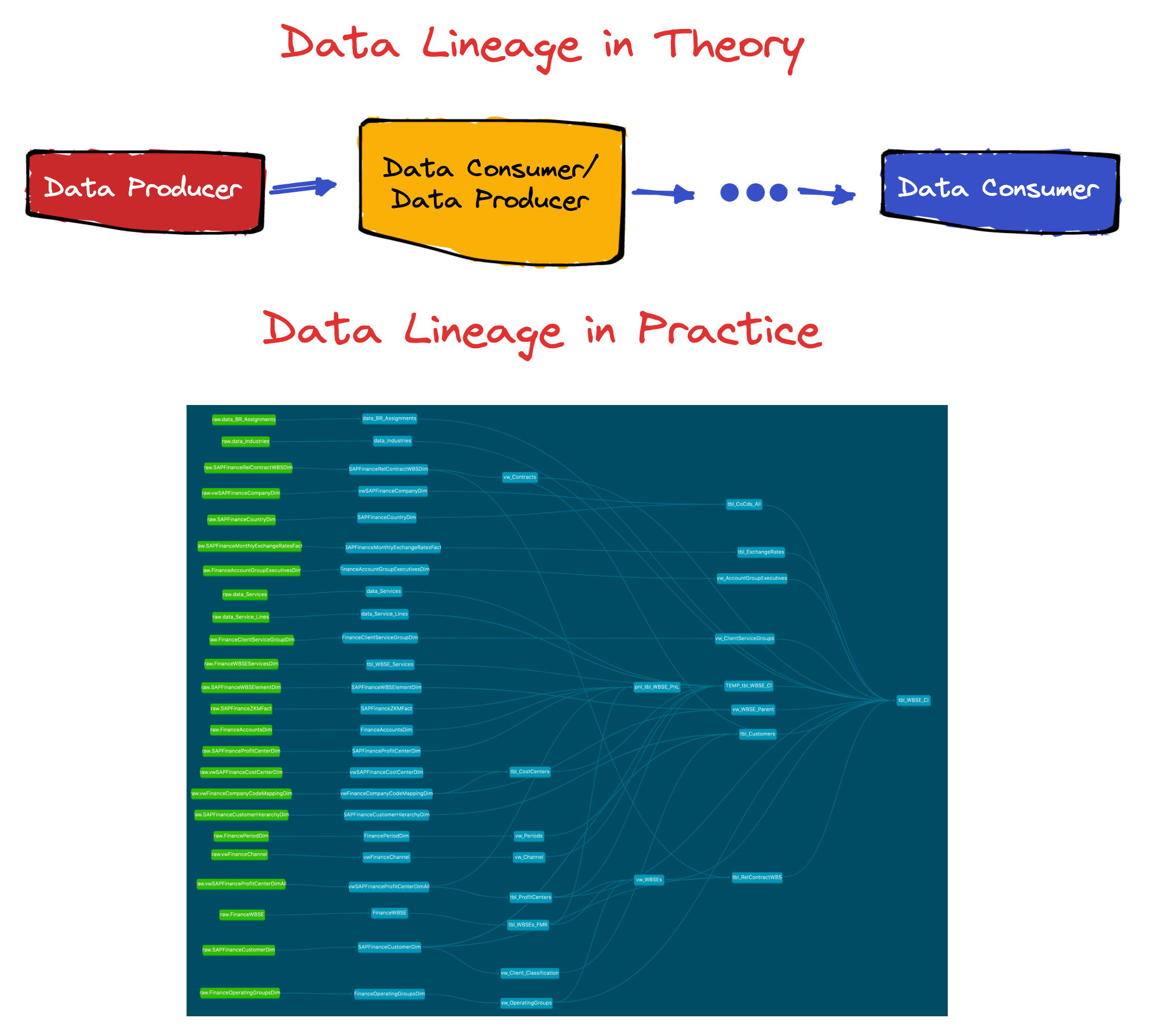
Data Contracts are an increasingly popular approach to mitigate this problem by having Data Consumers set a schema to test against in lower environments to prevent the Data Producer from breaking their input data before hitting production.
This is the only way to manage downstream breaks and it is necessary friction.
Some Common Mistakes

Here is a non-exhaustive list of ways I have blown up a server over the last decade:
Featurization Errors
Quite literally just a bug when creating a feature (e.g,. accidentally dividing by zero before trying to execute a multiplication will make your computer go boom 🤯)
Machine Learning Library Errors
Most practitioners are using the same machine learning libraries (e.g., pytorch, glmnet, xgboost, sklearn, tensorflow, keras, lightgbm) but often those libraries have very specific C++, Fortran, or other dependencies that are run on someone’s laptop and not on the server being used to run the model. Docker fixes this.
Loading Model Errors
Make sure your model literally fits in your server.
Service Errors
Make sure you have some exception handling for when your model breaks. Don’t give your customer a bad user experience because of poor planning.
Business Logic Errors
If you do something to your model after you execute some multiplications, make sure you test the behavior.
Statistical Errors
Make sure your training data was a representative sample and if it’s not, monitor the performance closely.
Overall, many of these errors can be avoided with some simple choices but ten years ago this was not as obvious to me.
Risk and the Engineering of Chaos
I wrote an entire article about this.
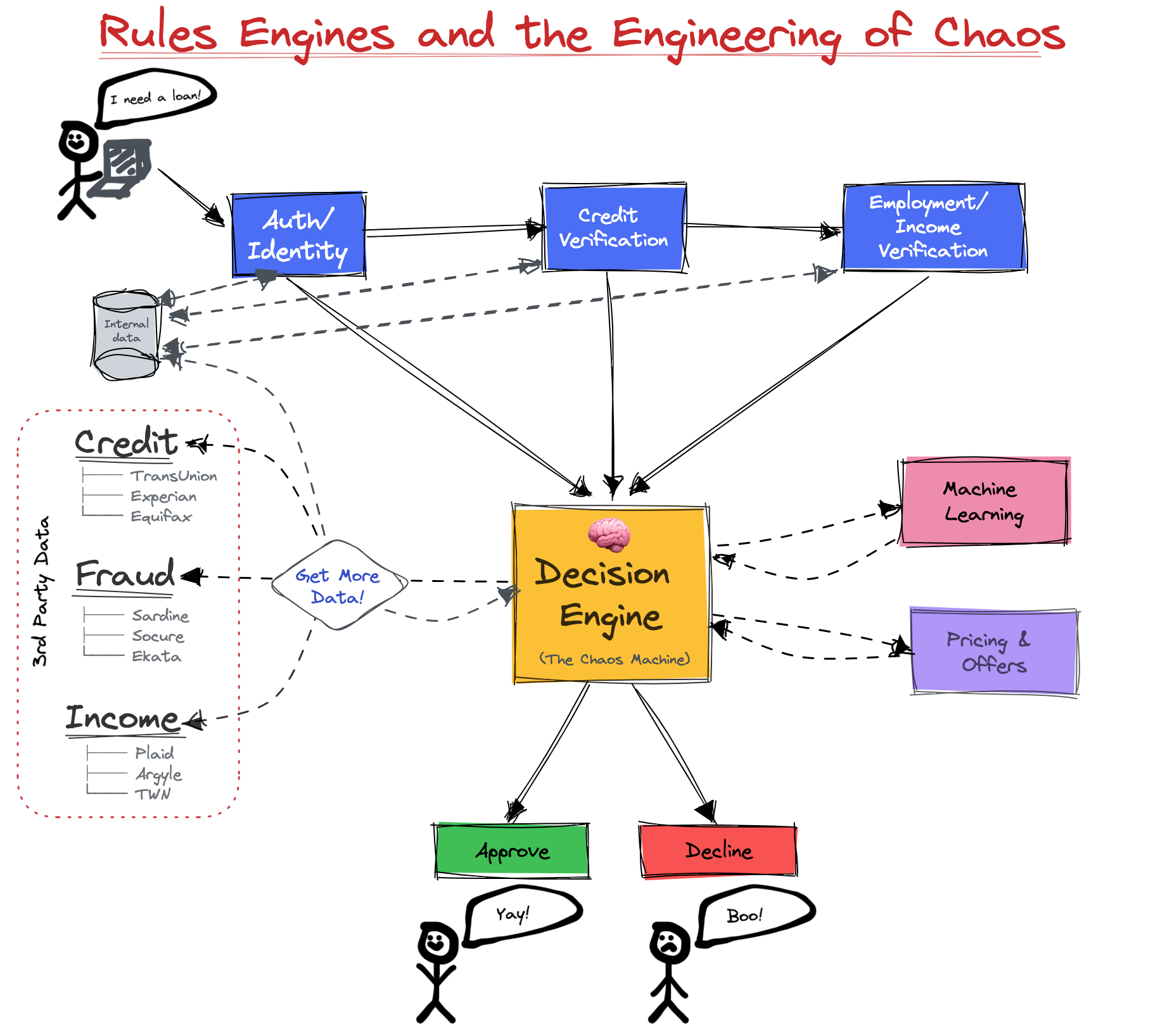
Modeling risk means you are modeling chaos. Rules impose order on chaos. Rules tend to spiral into chaos themselves. Know that your model plays an important role in a large ecosystem of entropy.
The Demo
As mentioned, the code is available here.
The main focus is on how Feast can play a critical role in mitigating some of the significant challenges that I experienced in the past and the demo aims to highlight that.
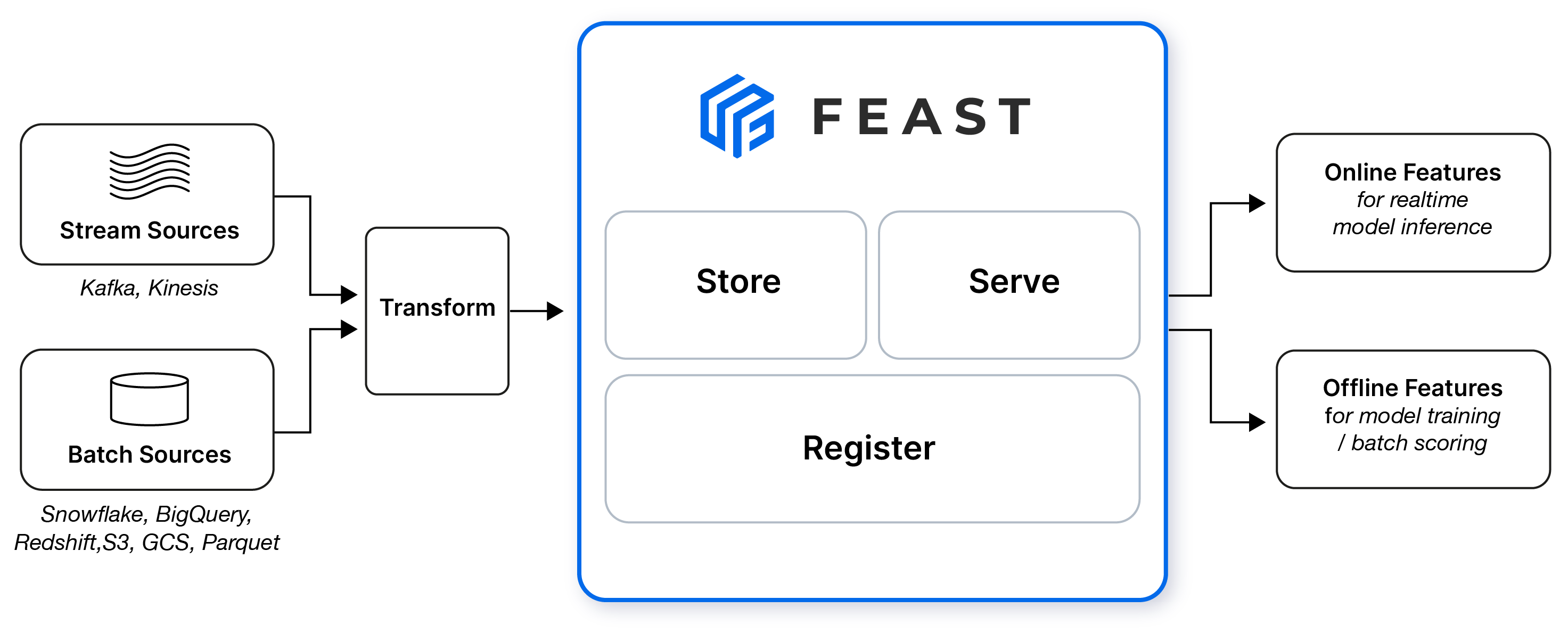
I won’t go over all of the many things Feast supports out of the box but it is a rather comprehensive tool that is used by some of the best technology companies in the world (*cough* Affirm *cough*).
The demonstration shows what a real ML risk system could look like for onboarding a driver to a driving app and then monitoring their risk daily.
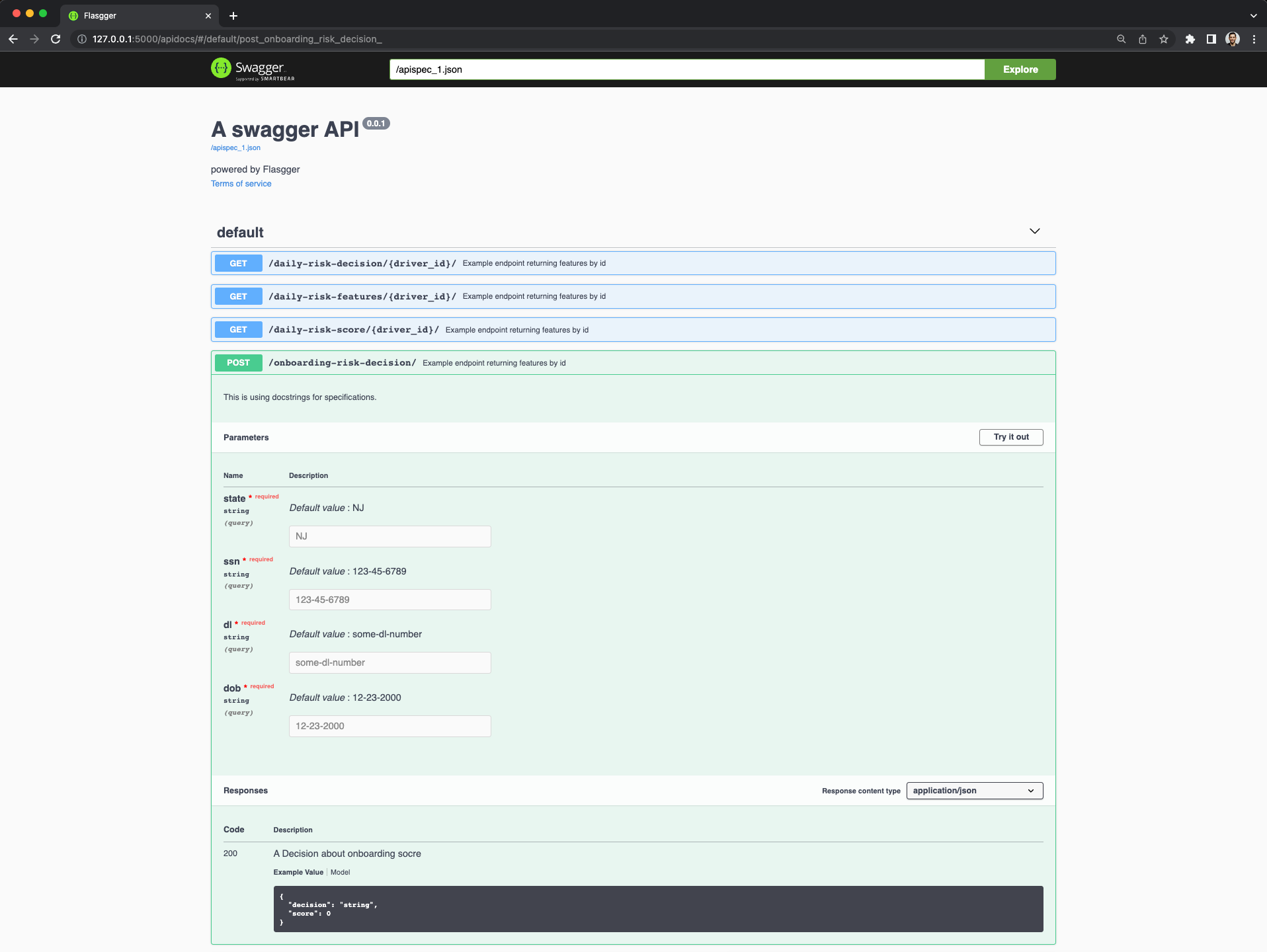
There are two models, an onboarding model and a daily batch2 model. The onboarding model takes an input form with four fields:
State
Social Security Number
Driver’s License
Date of Birth
Since all of the data is in the form, we have to use that data to construct the features, I do this in Feast using On Demand Feature Views, which works great. Then I toss those constructed features into my model, get a score, and then make a decision.
For the daily model, I use six features calculated from a batch run from “yesterday”:
Yesterday’s Conversion Rate
Yesterday’s Acceptance Rate
Yesterday’s Average Number of Trips
Yesterday’s Average daily trips < 10
Yesterday’s Acceptance Rate < 0.01
Yesterday’s Conversion Rate > 0.80
And here, because we can precompute the features, there’s no need for a dynamic computation so we just look up the features at request time. This is called a Feature View in Feast and the batch use case is the most basic one. Similar to the Onboarding model, I fire the features to the model after retrieving them, get a score, and then make a decision.
I also included a clunky little UI to show what the user experience could look like—the UI was unnecessary but it makes it feel a little more concrete.

The whole thing (i.e., the ~660 lines of Python code) boils down to three APIs.
def get_onboarding_features() -> Dict:
# done via Feast
...
def get_onboarding_score() -> float:
# done via a fake regression but you could imagine using a
# more sophisticated machine learning model
...
def get_onboarding_decision() -> str:
# done using the score and a simple threshold operation
...And the three APIs can be reduced to one with two being called behind get_onboarding_decision(), which is the API you would want to expose to some client, probably.
Maybe one that would do something like this:
In practice the get_onboarding_features() part involves a lot but the point is to highlight the separation of responsibilities for the purpose of understanding where common things explode.
If you look at the code, Feast handles a lot for you. Especially many of the gotchas that come up when working in data and machine learning. I won’t elaborate on all of the ways it handles it because their docs really are much more useful than this post but suffice it to say that it’s a powerful framework.
Closing Thoughts
Machine Learning is quite popular in the media today due to LLMs, and this past week it appears to be 5x for the chip makers but people seem to be forgetting that model training and inference are the last steps in the ML pipeline. Data and software are the foundation and lifeblood.
If GPUs are the picks and shovels then data is the mountain.
Happy mining!
-Francisco 🤠
Some Content Recommendations
Fintech Brain Food 🧠 wrote a fantastic piece on The Future of Generative AI in Fintech and it’s, you guessed it, Decentralized. It’s a great piece and Simon articulated my thoughts 1000x better than I could.
Jason Mikula at Fintech Business Weekly wrote an exceptional piece on SoLo Funds deceptive practices and some of Revolut’s current troubles.
SeattleDataGuy wrote a great piece on what Data Engineering has gone through over the last decade.
Postscript
Did you like this post? Do you have any feedback? Do you have some topics you’d like me to write about? Do you have any ideas how I could make this better? I’d love your feedback!
Feel free to respond to this email or reach out to me on Twitter! 🤠
The Pragmatic Engineer was taken but the Pragmatic Statistician doesn’t sound as cool.
In practice this would be done with Spark, Airflow, and more advanced machine learning libraries but that all would distract from the key point in this demo.