
Open Sourcing OpenAI
Intelligence, Step Into the Light


Any sufficiently advanced technology is indistinguishable from magic.
— Arthur C. Clarke
OpenAI
We live in a post-intelligence world thanks to OpenAI.
Before your fingertips exists the cumulative knowledge of humanity and we have the privilege of taking it for granted—all because of ChatGPT.
But, as I have said before, neither a single company nor a small set of companies should be the gatekeepers of AI. AI must be open.
For a brief moment in time, AI Doomers fear-mongered legislation to prematurely curtail AI innovation with the premise of an existential threat to humanity—such claims are and always were childish.
While the P(doom) claims were silly, they struck a chord with millions of people and for good reason. AI can be overwhelming when one first interacts with it. Seeing a software agent write perfect code can feel simultaneously exciting and terrifying…but that is because it feels like sorcery.
When we don’t understand things, fear is natural, which is why it is necessary to shed light on AI.
That is why open source matters.
Open source strips away the illusion. It demystifies the machinery. It allows the world to inspect, understand, modify, and ultimately trust these systems.
No mystery. No sorcery. Just code.
Into the Light
I spent the bulk of the past year in a labor of love with Open Source to demystify that sorcery and I am proud to share that I have satisfied my initial goal1.
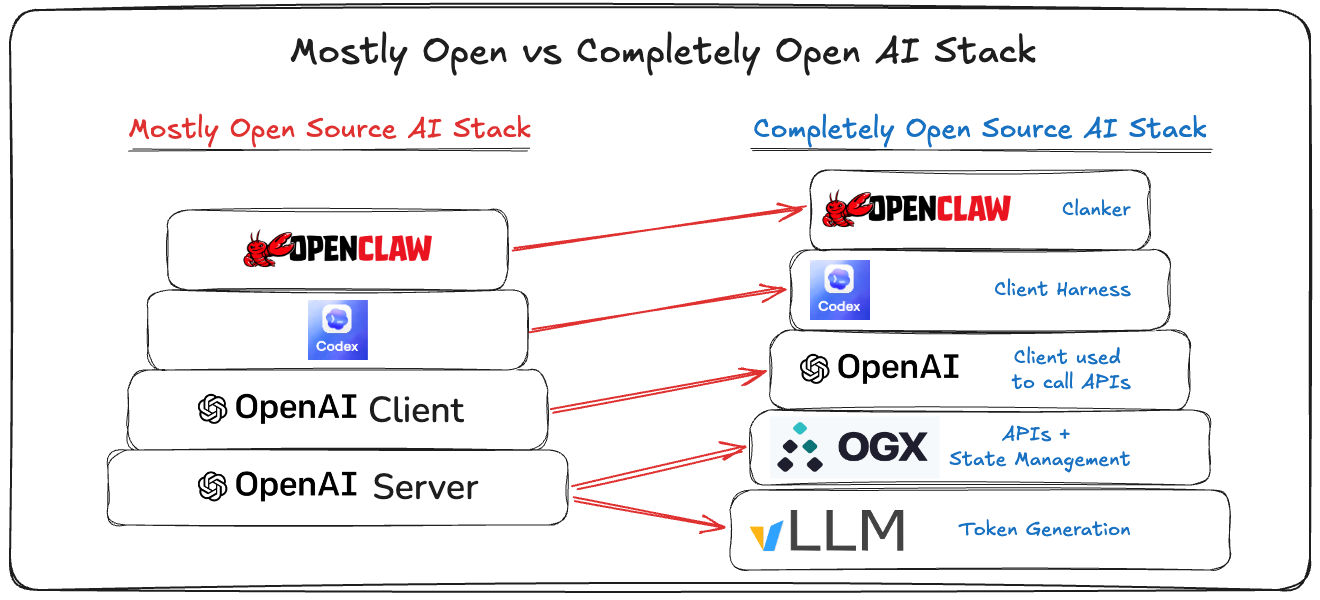
Most people using AI use OpenAI through (1) one of the OpenAI clients, (2) ChatGPT/Codex, and (3) OpenAI’s SaaS product (their API and token generator). And, increasingly, with OpenClaw on top.
OpenAI’s clients are open source, Codex is open source, but OpenAI’s SaaS product is not open source.
Their SaaS product is a a set of APIs centered around the Responses API.
The Responses API is a server side agent loop with state management, tool calling, and godlike token generation.
While the SaaS service is obviously not open source, OpenAI did launch Open Responses, which provides an open specification for conformance to their API. This is important because it creates an open standard the community can align on.
That matters because the Responses API is what OpenAI—the frontier leader of AI—claims is the best way to build agents.
We designed Responses to be stateful, multimodal, and efficient.
— OpenAI
And now we have open sourced this, too, bringing Responses, and its surface area, into the light.
Introducing OGX: Open GenAI Stack
I, along with an extraordinary team of engineers2, forged this project together3.
So I am excited to introduce OGX, an OpenAI-compatible agentic server with first class support for open weight models.
Why build this?
Again, it is critical to unveil the mystery behind the Responses API and show the world what is underneath.
The magic of the Responses API is not magic at all. It is the orchestration of transcendent token generation, state management, retrieval, tool execution, and business logic behind a unified interface that feels deceptively simple to developers.
OpenAI’s Responses API
So how does the Responses API actually handle the agent loop, tool calling, and persistent state?
The figure below provides a high-level view of that.
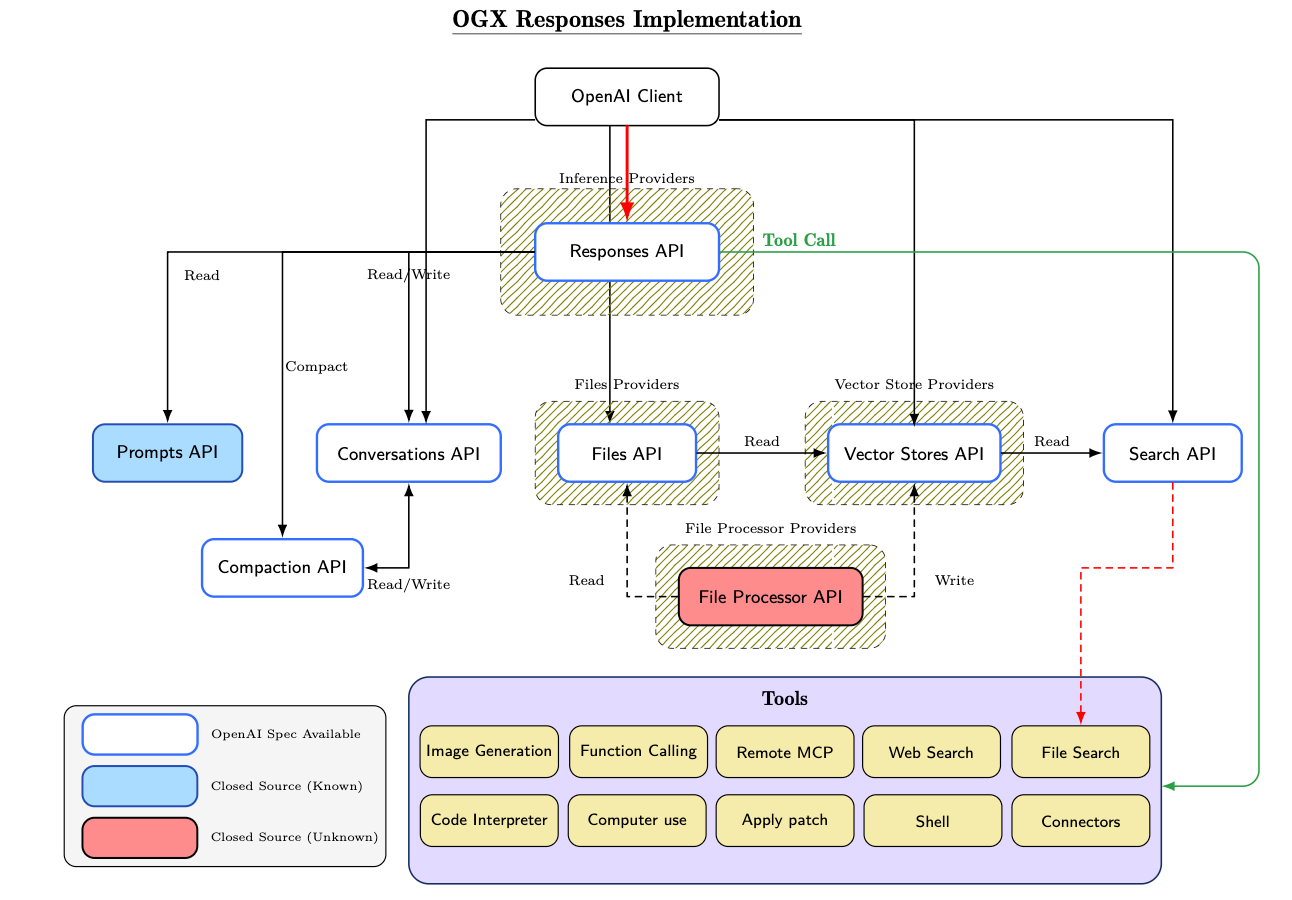
As the diagram illustrates, the surface area required to fully implement the Responses API paradigm is substantial.
Note, the complexity is even greater than shown here, as this diagram omits the Skills API, Containers API, and Shell tool entirely.
Why go through all of this trouble? Because abstraction matters.
The entire purpose of the Responses API is to transform distributed systems complexity into an interface that feels almost magical to developers.
import io, requests
from openai import OpenAI
url = "https://www.paulgraham.com/greatwork.html"
client = OpenAI()
vs = client.vector_stores.create()
response = requests.get(url)
pseudo_file = io.BytesIO(str(response.content).encode('utf-8'))
file_id = client.files.create(file=(url, pseudo_file, "text/html"), purpose="assistants").id
client.vector_stores.files.create(vector_store_id=vs.id, file_id=file_id)
resp = client.responses.create(
model="gpt-5",
input="How do you do great work?",
tools=[{"type": "file_search", "vector_store_ids": [vs.id]}],
include=["file_search_call.results"],
)
print(resp.output[-1].content[-1].text)With just a little bit of code, we now have fully agentic RAG.
No manual chunking pipelines. No embedding orchestration. No retrieval infrastructure. It just works™.
But simplicity at the surface requires intense complexity underneath.
And once these systems become infrastructure for enterprises—and perhaps society itself—security stops being optional.
That became the foundation for our research.
The ACM Conference on AI and Agentic Systems (CAIS)
Beyond the excitement of publishing our production-grade, open-source software, I’m proud to share that our paper, “Securing the Agent: Vendor-Neutral, Multitenant Enterprise Retrieval and Tool Use”, was accepted to the ACM Conference on AI and Agentic Systems (CAIS) 2026.
The paper formalizes the architecture and security model behind OGX and the Open Responses paradigm underpinning enterprise-grade agentic systems.

This is a deeply meaningful for me for several reasons:
Validation of the technical ideas and architecture
My first academic publication
I wrote4 over 700K+ lines of code on nights and weekends to build this
And open source made this possible.
Open Responses
I am especially grateful for OpenAI, who have been incredible supporters of the open-source community.
Without OpenAI creating Open Responses, open sourcing their gpt-oss class of models, the OpenAI clients, and Codex, none of this would have been possible.

It is especially validating that OpenAI has recognized the work we have done in Open Responses.
The Burden of Open Source
It is not enough to be open.
We do not earn trust through dogma—it is earned through hard work. Open systems must compete on technical merit.
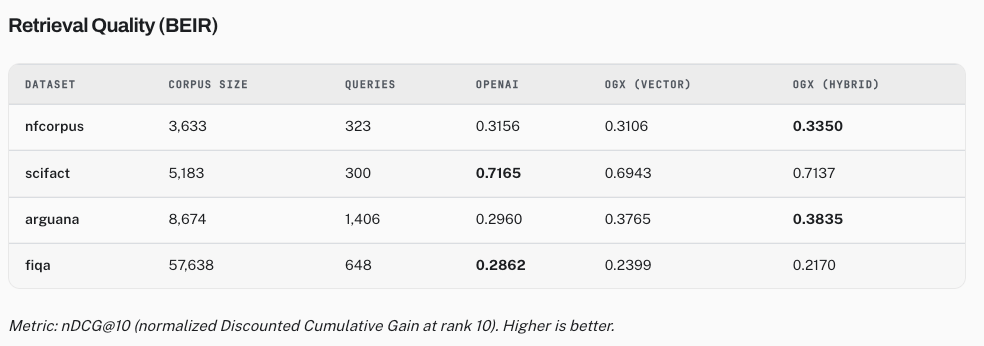
To evaluate the effectiveness of Open Responses and the architecture behind OGX, we ran a comprehensive agentic RAG benchmark suite spanning retrieval quality, latency, security isolation, and multitenant behavior.
The results were compelling.
Across academic retrieval benchmarks, OGX demonstrated that open agentic systems can be competitive while enforcing strict security boundaries. More importantly, the results suggest that security and developer experience do not need to exist in tension.
That matters because there are ultimately only two parts to an LLM system:
Retrieval: context injection
Inference: token generation
Everything else is orchestration around those two primitives5.
The quality of an “intelligent” system is often constrained less by token generation itself and more by the quality of context injected into the model.
This is precisely why Open Responses matters.
The Responses API paradigm transforms retrieval, tool execution, state management, and orchestration into a unified abstraction that simplifies the developer experience while creating centralized enforcement points for security, policy, and multitenant isolation.
But open systems cannot merely compete on ideology. They must compete technically. And increasingly, they do.
But the fight for open intelligence is far from over.
The Fight for Open AI
The price of freedom is high, always has been. And it’s a price I’m willing to pay. And if I’m the only one, then so be it. But I’m willing to bet I’m not.
Artificial intelligence is the most consequential technology of my lifetime.
It is already accelerating drug discovery, helping solve complex mathematical problems, generating software, synthesizing scientific research, and transforming how humanity interacts with knowledge itself.
The stakes are simply too high for the future of intelligence to be controlled behind closed doors by a handful of organizations.
The world does not need more fear, it needs more understanding. I want America to lead the world in open-source intelligence.
Open source is how we demystify these systems. It is how humanity participates in the construction of intelligence itself, and openness cannot stop at the model weights. The entire stack matters:
training data
training infrastructure
inference
retrieval
state management
orchestration
tools
evaluation
and agentic runtimes.
Every layer plays a critical role in shaping on-demand intelligence.
The fight for Open AI is ultimately a fight to bring intelligence into the light—to make these systems transparent, understandable, and buildable by anyone.
But the future is not yet built. Forge it with me.
-Francisco
Some Content Recommendations
Peter Steinberger shares how he built OpenClaw, the most popular open source AI project on TED.
Jensen Huang’s NVIDIA GTC 2026 Keynote was extraordinary.
Max Levchin, CEO of Affirm, did an incredible interview with Molly O’Shea.
Simon Taylor wrote an excellent piece called “🧠 AI at the Checkout > AI Checkout”.
Post Script
Did you like this post? Do you have any feedback? Do you have some topics you’d like me to write about? Do you have any ideas how I could make this better? I’d love your feedback!
Feel free to respond to this email or reach out to me on Twitter! 🤠
Obviously, the job’s not finished.
I would like to express deep gratitude to maintainers, contributors, and community members supporting OGX, especially those from Meta and Red Hat.
This is the true virtue of open source.
Okay, me and Claude, also some simple code gen, but you get the point.
Memory and compaction are a retrieval and inference problem.