


ChatGPT Learns Fintech
On Implicit Learning and Suboptimality

“The illusion that we understand the past fosters overconfidence in our ability to predict the future.”

The excitement behind ChatGPT and the latest innovations in AI continues. Bing has launched an integration with ChatGPT, Google is on its way with Bard, and Amazon is stepping up to the plate by partnering with HuggingFace.
What a time to be alive and to be in machine learning!
A lot of folks in the Fintech space have been writing about Generative AI in Fintech (I did back in late December) but, rather than write, I thought I’d actually try something I discussed in one of my previous articles.
In short, I called out the problem with ChatGPT being wrong and I gave an example of asking questions about a checking account. Being the empirical person that I am, I decided to give it a try to see how ChatGPT actually does.
Can ChatGPT Learn Fintech?
Yes and no.
Note: I am being imprecise in my language intentionally. I am using “Fintech” and “transaction data modeling" interchangeably even though “transaction data modeling” is one example of a Fintech use-case. This is because transaction data modeling is a great consumer Fintech example that just about everyone can relate to, but the conclusions generalize more broadly…at least, that’s my opinion.



The current model architecture was trained on raw internet data, which is mostly written language. I’ve said before that Financial data is chaos (and tabular) due to the exhausting number of rules at play, which is a very different underlying structure than language.
This fact makes it non-trivial for ChatGPT to learn the same things that Machine Learning Engineers (MLEs) working in Fintech usually construct using their expert knowledge and general intelligence (*winks at audience*).

As an example (and in my tweet above), I gave ChatGPT ~80 of my credit card transactions and asked for very little…and it said a lot!

It was able to compute aggregations, summations, and even an arg max on the data. This makes sense because ChatGPT was trained on lots of code itself so it probably had seen lots of examples of how to do exploratory data analysis (EDA). Note that some of the computations were wrong but I could probably be more explicit in my prompts to get the results I wanted.
Asking ChatGPT to summarize a sample of transactions is doable because it has access to a small amount of memory (approximately 4,000 tokens ~16Kb) which means it can remember this sample of data.
For something other than a trivial example, this becomes a distributed systems problem—maybe easily handled by Snowflake or BigQuery but it is irrefutable that ChatGPT can no longer fit large amounts of data in memory.
What needs to happen for ChatGPT to learn Fintech?
You’d need a hybrid architecture where ChatGPT also learns to model a specific objective.
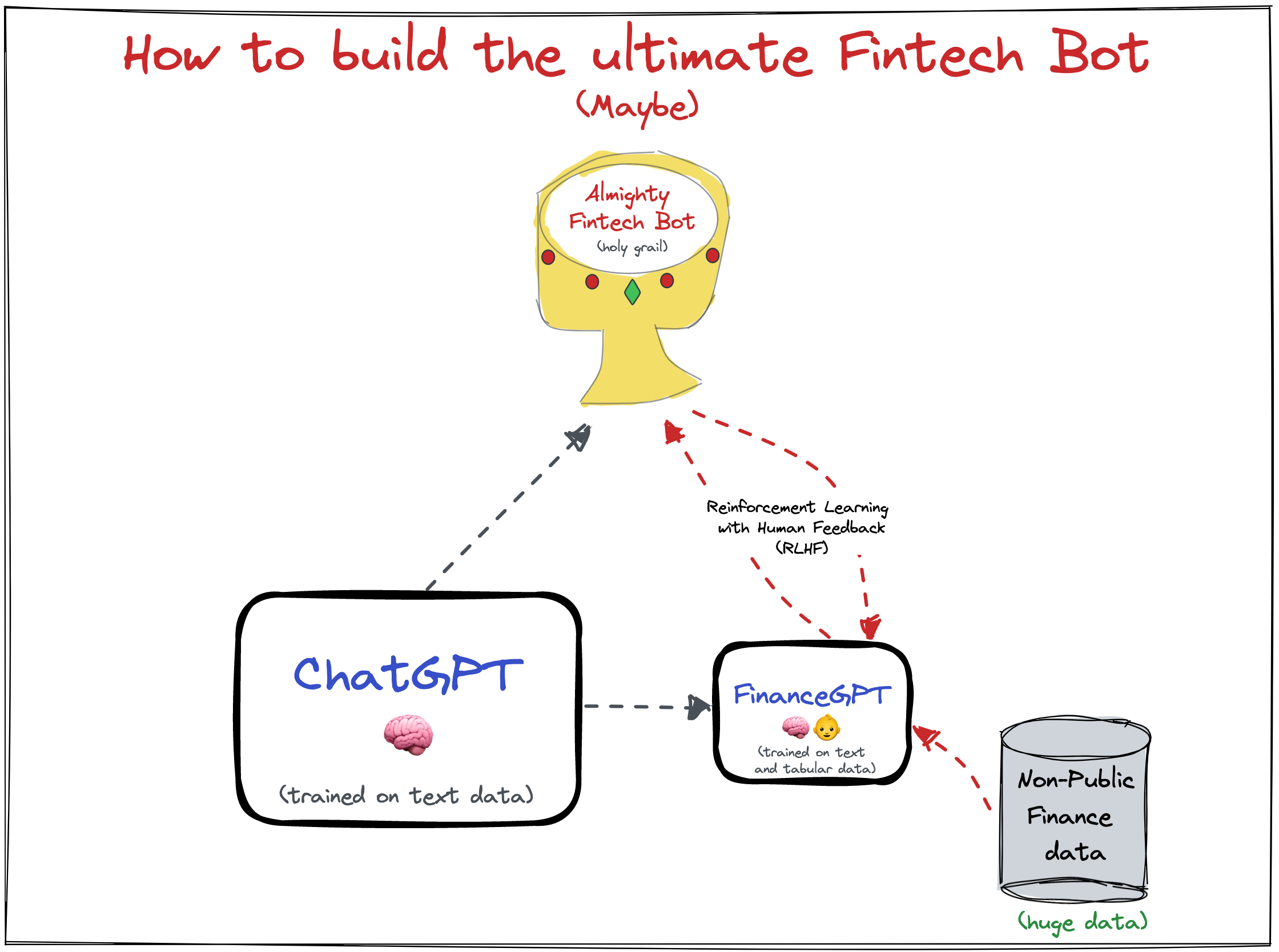
In technical terms, that means that you need to have an explicit ML model that can be optimized for this task, which means you need to take transaction, ledger, lending, and other financial data and pair it with textual descriptions. This is a form of Fine-Tuning where you’d use the pretrained model from ChatGPT and build on top of it specifically for large scale transaction summarization or other financial tasks. In this particular case though, you’d need to update the architecture to support the data as it is not just raw tokens (i.e., a word mapped to a number) it is mostly dense, numeric “tabular” data.
This explicit architecture makes sense because ChatGPT won’t learn the idiosyncrasies of finance as a subproblem because it doesn’t have access to terabytes of sensitive financial data. If you want to optimize it for that domain, you need to train it on the appropriate data and express that formally with a model that uses the best of both worlds.
This is a fairly common practice and using pretrained models really started with Word2Vec by Google back in 2013, so I’m not proposing anything novel here.
To briefly elaborate about what a “”hybrid architecture” means, LLMs and Neural Networks, at their core, are a series of matrix multiplications on some input data. A hybrid architecture would use the learned weights from ChatGPT as starting values for training and add an additional set of weights and layers to handle the banking features (specifically to express the numeric and dense nature of money stuff). The obvious limitation here being that while ChatGPT does let you run Fine-Tuning, they definitely don’t give you access to the underlying weights.
It’s worth noting that ChatGPT or FinanceGPT as I’ve named it here will never be perfectly accurate (humans aren’t) but this would help reduce the error in a much more structured way and probably within a reasonable tolerance.
Closing Thoughts
The conclusion is simple: ChatGPT will learn superficial stuff about finance, but in order for it to become a financial expert, it needs to be explicitly trained to be.
Intuitively this makes sense because ChatGPT is a generalist about internet knowledge and a specialist in programming because it was fed that data and reinforced. Once trained on and optimized for financial data it can learn that, too.
Theoretically you could try to feed the data as is to ChatGPT’s Fine-Tuning, but you’d probably do better by changing their neural architecture to explicitly model the structure of the financial data, which, as said before, is much different than text alone.
For example, I could feed in this entire article to ChatGPT and the sequential nature of language and contextualized multi-representation of words allows for some fuzzy notion of an agenda (written by me) with some variance in interpretation (by the readers)…but I couldn’t feed in a raw database from a bank and expect the model to learn anything (mostly because the data is just random numbers) so finance is often missing context that is well understood by humans, which is why you need a language model complimented by a financial one. The first model learns linguistics and logic, the second understands the behavior of financial systems—just like quants/MLEs do.

At least, that’s how I’d do it if I had tens of millions of dollars to burn through on Azure credits.
Happy Learning!
-Francisco 🤠
Some Content Recommendations
Alex Johnson had an incredible interview with Frank Rotman. Frank is one of the brightest minds in Fintech. His balance of technical/quantitative acumen and pragmatism along with his extraordinary legacy building Capital One to the Goliath it is today, makes 45 minutes with him feel like an extraordinarily high yield usage of your time.
Alex Johnson’s article on Generative AI is largely what inspired me to write this article and I highly recommend reading it!
Ron Shevlin wrote an incredible piece on the alternative to VC for enterprise Fintech
wrote an extraordinary piece at Every on how Stripe Can't Lose. I highly recommend subscribing to his newsletter (Batch Processing) as he does very thorough analysis and has the impressive background to justify it! wrote a pretty hot take stating "There is a strong argument to be made that the CFPB could use this authority to bring Apple and Google’s app stores under its supervision." I don't entirely disagree but I do think there are significant tradeoff decisions. Neither Apple nor Google would want that level of scrutiny as it would result in significant friction for developers creating new apps, which would ultimately decrease the utility of their respective app stores and thereby make their customers less happy. I think it's a worthwhile discussion but my guess is it'll be a very litigious one.Macroeconomist
wrote how The Fed alone cannot bring inflation down. I loved it. She’s a former Federal Reserve and White House economist and provides a terribly thoughtful view of our current economic environment.Postscript
Did you like this post? Do you have any feedback? Do you have some topics you’d like me to write about? Do you have any ideas how I could make this better? I’d love your feedback!
Feel free to respond to this email or reach out to me on Twitter! 🤠