
Building an AI to Scan Toxic Tweets 🔎
How to build a machine learning web application

I built one. You can try it here.
Update: I have since retired this service but the code is fully available here.
Who is this for? 🤔
This post is an overview of how to build an AI/ML application for a non-technical audience.
Some history 🤓
I love machine learning.
During my second master’s degree I dedicated most of my coursework to ML but throughout my career I found that going from a model working on static data to a model interacting with a live product to be extremely challenging.
I ended up shifting my entire career to making this problem easier by working at the intersection of data, machine learning, and engineering. I wrote about it briefly before but suffice it to say that I find this area of work intellectually fulfilling as new puzzles always arise.
Building a trivial tool to do this seemed like a fun exercise…but after some additional thinking it ended up taking a little more effort, so I thought I’d write about what a system like this would look like.
Machine Learning Systems 🤖
Building ML systems is quite hard, the short version is that there are a lot of potential gotchas that come up when building them (see here for a more technical discussion).
For those unfamiliar, Supervised ML systems take some inputs (often called features, predictors, attributes, etc.) and scores them to create an output (often called a prediction or score). As an example, your last month's credit utilization is a feature used in the model that predicts your credit score (a prediction measuring the probability that you will repay debt).
In that blog I gave a list of the top 10 lessons1 I have from 10+ years of building ML systems on tabular data which are:
Create strict contracts with the input source of your features
Test your feature engineering more than you want to
Codify the range and scale of your features
Separate your model execution from your feature engineering
Separate matrix serialization from model execution
Avoid mixing business logic with statistical operations
Precompute what you can
Load your model at service build time
Right size your server
Monitor your model and features
You don't actually have to do anything on this list to build an ML system, I just recommend it. Much of this stuff may not even make sense to build at an early stage but at a larger scale they become increasingly more important as preventative and defensive measures.
Lastly, I ranked these in order of importance and the most important ones are all preventative change controls, i.e., they can all detect breaks before you deploy something to production in unit tests. Defensive change controls are great too but one should remember that these will always come second place to preventative controls simply because you're catching a mistake after it's in production.
Funnily enough, many of these didn’t apply for this example but I recommend this checklist for professional applications that can’t risk breaking.
For those that are new to building ML systems I highly recommend Chip Huyen’s latest book: Designing Machine Learning Systems: An Iterative Process for Production-Ready Applications.
What’s needed to build a Toxic Tweet Scanner? 🧐
The goal is for a person to be able to submit a single form with a Twitter user’s username and see that user’s problematic/toxic tweets.
This requires some things:
A web application where a user can submit the username
A place to host this application somewhere on the web
Scanning through all of the user’s tweets (potentially tens of thousands)
A way to determine whether a tweet is problematic and store it
Allow a user to search for multiple twitter users and still be able to display the tweets intelligibly
Save a user’s history of requested twitter users
That doesn’t sound terrible but it does take work.
Solution Overview 👷♂️
Let’s address each requirement specifically:
I used Django, as it’s a pretty popular web framework and I find it to be flexible enough. It’s written in Python and since Python is the primary language of machine learning, it was a natural choice.
I wanted to tinker with a new deployment framework. I’m very familiar with GCP, AWS, and Heroku, so I chose Render because it supported Django trivially and it was new to me.
Twitter has great APIs available and it was very easy to set up a new API Key. Creating a long running asynchronous task to fetch all of the user’s tweets required me to use a Celery Broker so that the application wouldn’t time out while processing thousands of tweets.
I used a pre-trained BERT language model developed by Laura Hanu at Unitary to determine which tweets were “problematic” and stored the predicted toxicity store in a PostGreSQL database.
A simple solution was to just have users be redirected to the list of users they searched after submitting the form and then displaying the full list of tweets based on the selected user and paginate the scored tweets.
This requires some form of authentication so that we can store a user’s search history. I chose to add authentication with Twitter as a fun enhancement.
So, at a high-level, the application should look like the diagram below:

And for the most part, it does! The entire code is available on my GitHub, so you can fork it, deploy it yourself, modify it, or whatever else.
Some Facts 📝
This tool currently uses ~1,270 lines of Python code to accomplish all of this, which is not terribly much2. It’s about ~2,700 lines if you include configurations, HTML, and other important but not service specific code.
It certainly took me time to build this—especially while working a full-time job, writing a newsletter, learning Render, and debugging the gotchas I had to resolve.
If you look at the data I started this little toy back in March 2021 and paused it until July 2022 when I finally picked it back up again3, so that's a bit of a long timeline to finish this but the actual work was done rather quickly.
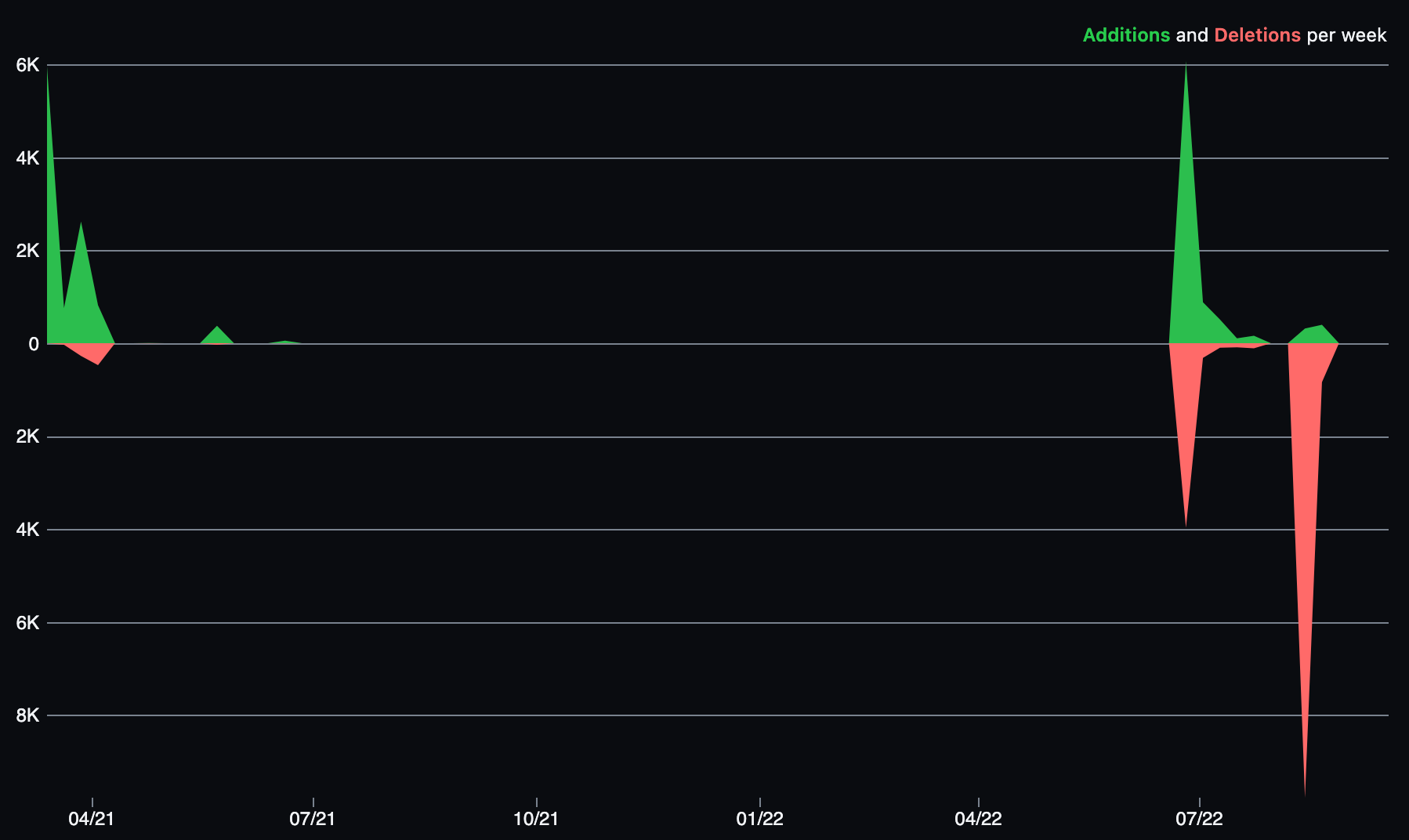
So what does it look like? 👀
I invite you to take a look at the code in the repository4 as it’s all there and it’ll help gain some understanding of what it takes to do something even this superficially simple. While I obviously can’t show you all 1,270 lines of code, I can show you a snippet of some of it:
def get_score_save_historical_tweets(
screen_name: str,
n_tweets: int = 20
) -> None:
print(f"getting historical tweets for {screen_name}...")
if not screen_name:
print("dummy task worked")
return None
# make initial request for most recent tweets
# 200 is the maximum allowed count
new_tweets = twitter_api.user_timeline(
screen_name=screen_name,
count=n_tweets
)
tweet_counter: int = len(new_tweets)
# keep grabbing tweets until there are no tweets left
while len(new_tweets) > 0:
# save the id of the oldest tweet less one
oldest = new_tweets[-1].id - 1
# all subsequent requests use the max_id param
# to prevent duplicates
new_tweets = twitter_api.user_timeline(
screen_name=screen_name,
count=200,
max_id=oldest
)
tweet_counter += len(new_tweets)
# save the most recent batch of tweets
score_and_save_tweets(screen_name, new_tweets, 5)
print(f"...{tweet_counter} tweets downloaded so far")
print("finished getting historical tweets")
def score_tweets(input_text: List[str]) -> List[float]:
predictions = model.predict(input_text)
return predictions["toxicity"]
def batch_score(
input_text: List[str],
batch_size: int = 5
) -> List[float]:
predictions = []
for i in range(0, len(input_text), batch_size):
batch_text = input_text[i : i + batch_size]
res = requests.post(
INTERNAL_MODEL_ENDPOINT,
data={"tweets": batch_text}
)
tmp = res.json()["predictions"]
predictions.extend(tmp)
return predictions
@transaction.atomic
def score_and_save_tweets(
screen_name: str,
tweets: list,
batch_size: int = 5
) -> None:
print(f"scoring all tweets for {screen_name}...")
tweet_text = [j[3] if j[3] else "" for j in tweets]
tweet_scores = batch_score(
tweet_text,
batch_size=batch_size,
)
print(f"saving all tweets for {screen_name}...")
for tweet, tweet_score in zip(tweets, tweet_scores):
tweet_date = datetime.strptime(
tweet[1],
"%a %b %d %H:%M:%S +0000 %Y"
).astimezone(pytz.UTC)
db_tweet = Tweet(
created_date=timezone.now(),
tweet_id=tweet[0],
twitter_username=screen_name,
tweet_text=tweet[2],
tweet_date=tweet_date,
toxicity_score=round(tweet_score * 100.0, 2),
)
db_tweet.save()
print("...scoring complete")
And that’s kind of the core of it.
Closing Thoughts 👋
I really enjoyed this exercise as it was a fun way to show how something that seems small can be complicated and I wanted to build something more than a Jupyter Notebook5, so this accomplished both of those pieces for me.
There are some important caveats that I want to make though as this example shouldn’t be seen as completely representative of how easy it is to spin up ML systems for your teams6.
I don’t have a ton of tests in this tool but for a real application you need them, which I outlined in my checklist above.
Running this on a tool like Render (a Platform as a Service) is great as I can easily scale up horizontally (i.e., more computers) and add infrastructure trivially (databases, queues, etc.). This is typically not true at scale when you manage your own infrastructure on Kubernetes and Terraform, which requires a lot more effort for very good reason.
I didn’t have to build a model in this exercise; I took an off the shelf one that a research team at Google spent months building (i.e., BERT). Building models is hard work and I really want to emphasize that I completely omitted it here and I don’t want to give the false perception that it’s easy to build an ML model to do anything (sometimes it is but that’s atypical).
Lastly, I open sourced the code as I thought it would be a good way for those that are unfamiliar with building a system like this to get familiar with it. Open source and blogs are really what helped me learn how to build all of this stuff, so I felt I should contribute something and I’m excited about the open source work I’ll be doing in the future (more on that later 😉).
I know this post is a little bit different than some of my last ones, so I hope you like it!
Happy computing! 🤖🤠
-Francisco
Postscript
Did you like this post? Do you have any feedback? Do you have some topics you’d like me to write about? Do you have any ideas how I could make this better? I’d love your feedback!
Feel free to respond to this email or reach out to me on Twitter!
Reading the list here it sounds rather boring but not everything in ML is glamorous.
I’ve mentioned before that this is a poor metric for understanding the complexity of something but I should emphasize it here for obvious reasons.
This is also attributable to my time at Fast, where I shipped an enormous amount of code. 🤠
I’ll add that there’s a lot I need to clean up in the repo but I wanted to get an MVP out and then refine it later—a habit I recommend to pretty much everyone.
Notebooks are great! But they have their limitations of course.
Though if you find you’re having significant problems, I would recommend seeking some help. You can reach out to me if you’d like!